2008年01月16日
SQLite の VFS
いつの間にか SQLite に VFS という仕組みが追加されており、これを使うことで任意のファイルシステムからデータを読み書き出来るようだ。
通常は何もしなくても使えるが、例えばアーカイブの中に入れた DB からデータを読みたい場合などはこれを使う必要があると思われる。
と言うことで、XP3 アーカイブ内に入れた DB ファイルから読み出せるように VFS を実装中。
とりあえず、一通りメソッドを書いた。
24個もあるので面倒だった。
動作確認はまだ。
これが出来ると、読み出し専用の DB をアーカイブ内に含めることができる。
大量にデータがある時は、RDB が使えると便利と言うか、ないと面倒臭すぎる。
書き出しは今のところ必要ないが、必要になった時は外に置く。
その場合、手軽に利用できるように O/Rマップの実装を考え中。
だいたい仕様は考えた。
その仕様どおりに動くとかなり便利なはず。
投稿者 Takenori : 01:23 | トラックバック
2008年01月19日
xp3_vfs
TVPCreateIStream によって取得した IStream 経由でデータを読む SQLite の VFS はできて動いた。
読み込み専用なのと、sqlite3_open_v2 を使っているので utf-8 専用になっている。
sqlite3_vfs_register でデフォルトに設定すれば、sqlite3_open16 でも開けるかと言うと、その場合はオープン時のフラグをセットできないので、読み込み専用で開けない。
VFS で読み込み専用じゃなくても開けるようにしてもいいが、XP3 に書き込みはできないと思うので、また面倒。
まあ、データベースの内容を一気に読み込まず、少しずつ必要時に読むだけであれば、変換のコストは無視できる程度だろうから、このまま utf-8 で行くことにした。
データの登録は Web 上から出来るように PHP で書いた。
Web 上から登録したデータは SQLite のデータベースファイルに入るので、登録したデータファイルをコピーしてくればそれがそのままゲームに反映される。
数人でデータを登録していくには便利。
後、PHP の PDO で SQLite のデータベースを読み書きする時に utf-16 で保存出来なさそうだったので、プラグイン側で utf-8 を使ったと言うのもある。
プラグインは初め汎用的にしようかと思ったけど、特化してしまった。
公開している API はそれ専用。
外部からはブラックボックスで、中でどのようにデータを取得しているかは不問。
TJS でゴリゴリいろいろ書いてもいいけど、プラグイン書くんだからということでそうした。
投稿者 Takenori : 18:30 | トラックバック
2008年01月22日
フォースフィードバッグで振動させたい
フォースフィードバッグで振動させたいと言うことで、ゴリゴリプログラミング中。
それで調べた内容などをメモ。
ゲームパッドを使うと言えば、Direct Input だけど、最近は XInput と言うのがある。
これは、Direct Input に比べるとすごくシンプル。
基本的には、初期化不要で Set と Get のメソッドで入出力を行う。
入力系統は、XBox360 のパッドと同じものと想定している。
パッドは4つまでとなっていて、Set や Get で数字を渡せばそのパッドの入出力が返ってくる。
なかなか簡単で便利そう。
ただ、XInput に対応したデバイスでないと使えない (今のところXBox360のパッドをPCにさして使う用?) 。
後、Direct3DX と同じわながありそう。
xinput1_1.dll、xinput1_2.dll、xinput1_3.dll と番号付の DLL がインストールされている。
つまり、これは DirectX がマイナーバージョンアップするごとに数値が増えて増殖するパターンのにおいがする。
で、リファレンスなどにしたがって Xinput.lib とリンクすれば、その開発時の SDK に入っている DLL で固定されると思われる。
カプコンのロストプラネットのFAQにはそのために発生していると思われる問題に関する記載がある Q. 「XINPUT1_3.dllが見つかりません」というエラーが出てゲーム起動できません 。
Direct3DX の場合は、昔のバージョンだとスタティックリンク版の物が存在しているため、そのバージョンの SDK を手に入れて、その lib とリンクすることで、dll ではまる問題を回避できる。
が、XInput は…… いろいろなバージョンの SDK を入れればあるかもしれないが、比較的新しいもののようだから スタティック版はないかもしれない。
とすれば、xinput1_3.dll に動的リンクして、リンクできなかったら XInput 使用不可とするか。
で、Direct Input を使用して動かす。
でも、XBox360 のパッドを Direct Input 経由で動かすと使えなくなる機能がいろいろあるんだとか。
トラップ絶賛発動中だなぁ。
まあ、昔のパッドならば Direct Input で問題なく動くだろうから、だいたいはそれで何とかなるだろうが。
後、普通に Direct Input を使って、デバイスを列挙すると、その中に XInput に対応したデバイスも引っかかる。
これの回避方法はサンプルに含まれていて、WMI を使って XInput デバイスのメーカーとプロダクトIDを調べて、Direct Input デバイス列挙時に同じのがあったら弾けばいけるようだ。
Windows Me、Windows 2000、Windows XP、および Windows Server 2003 では WMI が標準でインストールされると言うことなので、まあだいたい大丈夫。
それ以前のものは、WMI SDK や IE5 などをインストールしていれば使えると言うことのようなので、何とかなるといえば何とかなる。
Direct Input フォースフィードバッグの指定方法はいろいろあって結構複雑。
それぞれのパラメータの関係などを調べたが、XInput と同じようにただ単純に強さを指定し、コントロールはソフトウェアでする方法が良さそうだ。
ちなみに、Direct Input では、常に一定のフォースを発生する コンスタント フォース。
距離に応じて、フォースを変える コンディション、値の配列を渡してそれに従って働く カスタム フォース、周期的にフォースを発生させる ピリオド、徐々に大きくなってから、また徐々に小さくなるフォースを発生させる 傾斜フォースがある。
で、使うのはこの中の コンスタント フォース。
ソフトでその時に応じて強さを与えてコントロールしようと考えている。
他に Direct Input で問題となるのは、ボタンやキーの数がバラバラなこと。
これを回避するためにアクションマップと言うものが一応存在しているが、ジャンルを固定して云々とかで使いづらそう。
と言うことで、いわゆるキーコンフィグが必要になる。
入力系統は、XBox360 のパッドと同じようになるようにしようとしているので、それに合うようにコンフィグで設定してもらう必要がありそう。
まあ、ある程度は存在するキーやボタンから近いものに割り当てるが、ボタンの配置などはパッドによっててんでバラバラ。
メーカーとプロダクトIDでテーブルを持っていくつかのパッドにはそのままでいけるようにしようと思っているが、それは自分の持っているものか、データが手に入るものしか出来ない。
なんかパッドの対応はいろいろとやっかいだな。
投稿者 Takenori : 20:28 | トラックバック
2008年01月25日
炎のエフェクトとパーティクル
※ 2008/2/10 認識に誤りがあったので修正。詳細なアルゴリズムは後日アップ予定。
いろいろと燃える演出を入れたいなと炎エフェクトについて調べた。
簡単に見付かったのは以下のページ。
2005/2/2 (水) [炎エフェクト]
このページは Fire をベースにと言うか、そのままソースを少し変えただけのようだ。
エフェクト(2) 炎 については、ゲームエフェクトマニアックス (C MAGAZINE)を元に作っているようだ。
最初の方のアルゴリズムは、炎文字の作り方 プログラマにもできるPhotoshopの使い方のような方法を順にやっているに過ぎない。
昔とあまり変わっていない気がする。
具体的には、画像をぼかしながら上の方にコピーしていく。少しずつ薄くする。完全に上ではなくゆらゆらさせる。
それだけ。いたって普通。
で、どのようにゆらゆらさせるかだけど、バネの動きを模しているようだ。
最初はランダムに動きを決めるが、その後は対象画素頂点の周囲の数画素頂点の動きを使って動き方を変えている。
図がないとわかり辛いので、以下に図を貼る。
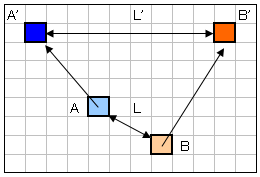
A が対象画素頂点、B が比較画素頂点。それぞれ A'、B' に移動する。
ここで、その画素頂点間の距離を求め、それぞれ L と L' とする。
で、( L - L' ) * 係数 として求めたものを L' にかけて、それを速度に加算している。
つまり、位置関係が離れる時は近づき、近づく時は離れるようになる。
その結果ゆらゆらゆれる。
単純に正弦波でもいいんじゃないのと思ったりもするけど、こちらの方がリアルになるのかな?
2個目の方はパーティクルの考え方とだいたい同じ。
HP ではなく、本のほうの解説をまとめると、ある位置からビルボードをランダムな速度で上の方に移動させ、徐々に薄くして、一定時間経つと消えるようにする。
単純なアルファ合成ではなく、加算合成を使う。
ここでふと昔書いたパーティクルのソースをあさってみた。
Cで書いていて、起動すると途中で落ちた。
確か、いろいろとリアルに見えるようにいじっていた記憶があるけど、なんでまともに動かない状態で止めているのかはなぞ。
だいぶ昔のなのでソースを見るといろいろとダメな点が見えるが、それなりに考えられている。
まず、パーティクルは出現時間、存続期間、現在位置、初期位置、速度、エネルギー、重力加速度、質量を持っている。
そもそも、重力加速度は個別に持つ必要はなくて、全体で1つでいいんだけど、なぜか個別になっていた。後、質量もいらないはず。
で、このパーティクルの初期値を乱数である程度の範囲で決めて、大量に作って動かすだけ。
ただ、描画するのは画像ではなくてエネルギー場(?)に対してで、コピーではなく加算になっている。
これは加算合成と等価な効果があるはず。
後、Z軸にしたがって、エネルギーが及ぶ範囲が変わるようにしている。
手前ほど大きくなるようだ。
後、特異点というものも持ち込んでいる。
パーティクルの中に、速い物が混じるようになっている。
これによって、爆発時に高速に遠くまで飛ぶものが混じる。
エネルギーから色への変換は単純なテーブルによって行われている。
このテーブルは赤→黄→白とRGB値が変化するようになっており、256+256+256の768段階になっている。
当時記憶では、PenIII 800MHzで、パーティクルを10万個ぐらいばら撒いたら 2、3秒に1回しか画面が更新されなかった気がする。
荒削り&適当っぷりが伺えるプログラムだな。
それなりに見えるものだったが、とにかく遅かった記憶がある。
と言うことで、以上を元にある程度使えるものを作ろうと考えている。
使えなかったら、その演出はカット。
初めは PhotoShop で作ったのをそのまま出せばいいと思ったけど、動いてなかったらつまらないと言うことで作ろうとしている。
投稿者 Takenori : 18:10 | トラックバック
2008年01月26日
ゲームパッド - デッドゾーンと飽和点
XInputの仕様と同じようにパッドは4つまでにしようかと思ったけど、制限を加える意味はないと気付いた。
と言うか、複数のパッドが接続されている場合、ユーザーに使用するパッドを選択してもらうことになると思うが、この時は見付かった全てのパッドが列挙される。
つまり、この段階では制限がない。
で、この後使うパッドが選択されて、決定されるわけだけど、ここで制限がある意味はないなと。
パッド数の制限は、ゲームのシステムによって決まるはずなので、同時利用可能なパッドの数はゲームのシステムに決定させればいい。
意外と知らせていないと言うか、自分が知らなかっただけだけど、コントロールパネル - ゲームコントローラで優先デバイスと言うものが設定できる。
優先デバイスが設定されていると言うことは、利用される可能性が高いかもしれないと言うことで、優先デバイスがあったらそのデバイスをリストの先頭に持ってくることにした。
その次にXInputデバイスが入り、後は見付かった順。
DirectInput ではデッドゾーンと飽和点が取得できるが、これはあまり意味がなさそう。
デッドゾーンとは、このアナログ軸の値がこの範囲にある時は、値を 0 とみなす範囲のこと。
アナログ軸の値をスティックを動かしたりして取得してみるとわかるが、手を離しても 0 にならず、小さい不定値になる。
で、この時動いていると見てしまってはいけないので、デッドゾーンを使って判定する。
飽和点は、反対にこの値以上になったら最大値とみなす値。
ただ、XInput では飽和点がないようなので、これはいらないのかもしれない。
で、これらの値を Logitech RamblePad 2 で取得してみるとともにないことになっている。
つまり、中心は 0 のみ、飽和点は最大値 となる (厳密には初期値は0~65535なので、中心は32768)。
でも、動かしてから手を離すと小さい不定値になる。
DirectInput の使い方を間違っているのだろうか?
検索してヒットしたソースを見たら、このデッドゾーンや飽和点を設定していたりするのがあって良くわからない。
性質からしてハードウェアの固有値だと思うのだが……
と言うことで、これらは XInput で定義されている固定値を使ってしまうことにした。
この値よりも大きい値で止まるパッドの場合、手を離しているのに少しずつ動いてしまったりするかもしれないが、そこは諦める。
まあ、一応デッドゾーンと飽和点をログに書き出して、キチンと値を設定しているパッドがあるかどうかは見てみようと思うが。
アナログ軸の値の範囲は、DirectInput に合わせて、-32768~32767に設定するようにした。
Logitech RamblePad 2 の初期値は、0~65535なので範囲的には同じ。
この範囲を扱えないパッドがあると、設定に失敗してしまうかもしれない。
DirectInput で対応デバイスを増やそうとしたら結構面倒かもしれない。
まあ、いろいろなデバイスで試してすんなり動いてくれれば、問題ないのだが。
投稿者 Takenori : 21:37 | トラックバック
2008年01月30日
HID のフィジカル デスクリプター
HID ( ヒューマン インターフェイス デバイス ) には、Physical Descriptors と言うものがあり、これで物理的な位置を取得できる。
位置と言っても、左手の親指で操作するボタンで、操作のしやすさもしくは距離は、いくつと言うような情報が得られる。
これによってゲームパッドのボタンがどの位置にあるかある程度わかると思ったんだけど、うまく取得出来ない。
まず、ゲームパッドから HID デバイスのパスを得るには、IDirectInputDevice8 の GetProperty で DIPROP_GUIDANDPATH を指定する。
これで得られたパスを CreateFile でオープンし、このハンドルを用いて HidD_GetPhysicalDescriptor をコールしてやることでデータが得られると思ったんだけど、うまく行かない。
普通にやると HidD_GetPhysicalDescriptor をコールするには、WDK が必要だけど、hid.dll を自分でロードしてやり、HidD_GetPhysicalDescriptor のアドレスを得れば、WDK なしでもコールできる。
HID 系のメソッドは、だいたいこの方法でアドレスを得られてコールできるようだ。
HidD_GetAttributes や HidD_GetPreparsedData、HidP_GetCaps、HidP_GetButtonCaps は普通にコールできて、値も得られた。
ただ、これらのなかには構造体のポインタを引数にとるものがあるので、WDK を使わないのなら、これらも自前で定義してやる必要がある。
HidD_GetPhysicalDescriptor で得られるのは RAW データとなっているので、これは自分で解析する必要がある。
Device Class Definition for Human Interface Devices (HID) ( PDF ) の 6.2.3 Physical Descriptors に記載されている。
また、HID Usage Tables ( PDF ) の Appendix C: Physical Descriptor Example には、その例があるので、こちらも見るとわかりやすい。
ってことで、このパーサは先に書いていた。
が、HidD_GetPhysicalDescriptor をコールしてもうまくいかない。
後、パッドによって動作が異なる。
何事もなく終了するが中身がからか、デバイスが機能していませんとエラーが返ってくるか、引数が不正で返ってくるか。
たぶん、使い方が悪いんだと思うが、良くわからない。
HID と直接通信するには、CreateFile で開いたハンドルを用いて、ReadFile や WriteFile で非同期で読み書きすればいいようだ。
つまるところ、自分でHID と通信してやれば、データを得られるのではないかと思う。
上に貼った HID の資料や MSDN2 のページを読んで、ひたすらトライアンドエラーを繰り返せば動かせると思うが、時間がかかりそう。
今は Physical Descriptors は置いておくことにした。
あっても少しだけ初期のボタン割り当てが、期待したものに近くなるだけだし。
投稿者 Takenori : 14:05 | トラックバック
2008年02月09日
VCのプロジェクトファイルを自動生成する
何かを作るとき、最初にソースファイルを作って、エディタで組んだ後、VCを立ち上げて、プロジェクト作って、ファイル追加して、オプションを変更して…… とするわけだけど、この「VCを立ち上げて云々」がすごく面倒臭い。
たいした作業ではないのだが、なんか気が重いのだ。
オプションもデフォルトから毎回同じ設定に変更している。
本来はカスタムウィザードを作って、それで何とかするんだろうけど、そこも面倒臭い。
ということで、スクリプトを組むことにした。
とりあえずは、吉里吉里のプラグイン専用で、kirikiri2/src/plugins/win32 以下に新しいフォルダを作ってその中にソース入れて作る用。
実行したフォルダ以下のソースとヘッダー、リソースを全てプロジェクトファイルに追加する。
また、ヘッダーが存在するパスも全部インクルードディレクトリに追加する。
これでフォルダ分けしている場合も、インクルードディレクトリのことを大して気にせず作業できる。( VC の GUI でやるとデバッグとリリース両方変更しないといけなくて面倒 )
スクリプト類は mkpj_kr_plugin.zip に置いておく。
設定などは私用になっているので変えたい場合は、project.pji を設定変更した *.vcproj に合わせて変更する必要がある。
プラグイン名は project.ini に書く。
mkpk.pl を見てもらえばわかるが、VCのプロジェクトファイル類を消してから作るので、取り扱いには注意すること。
*.vcproj を変えて mkpk.pl を実行してデグレードとかは注意しないとやってしまうと思う。
後、Win32-Guidgen モジュールを使っているので、ppm などで入れる必要がある。
他の注意事項は…… mkpk.pl を読んでください。
これは吉里吉里のプラグイン専用でVC2005用だけど、少し変更すれば exe などにも転用できる。
GUI でちまちまするのが嫌いな人は、自分用の設定で数種類作っておくといいかも。
投稿者 Takenori : 20:55 | トラックバック
2008年02月10日
パーティクルで炎は失敗
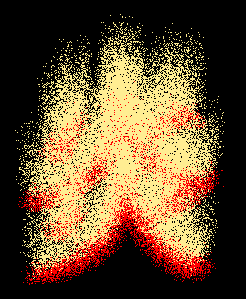
点描みたい。
これで約1秒間に1万個だったかな。
動いていても粒状感が消えないというか、まんまパーティクル。
ぼかしてもイマイチ。
数を増やせばある程度改善するが、どんどん重くなっていく。
いろいろといじってみるも、このアプローチでリアルに見せるのは難しそうだ。
ただ、パーティクル自体は何かに使えそう。
粒子が一方向に流れていると砂が飛んでいるように見える。
単純なパーティクルとして、パラメータを増やして実装するのはいいかも。
ということで、次はWrapマップの方で実装することにした。
元のままでは汎用性がないし、見た目も少しおかしくなる時がある。
アルゴリズムは理解したので、汎用性がありもう少し高精度な実装にしている。
投稿者 Takenori : 15:20 | トラックバック
2008年02月11日
Warp Map で炎


パーティクルはイマイチだったので Warp Map を使う方法で実装した。
静止画像でもだいぶリアルに見えていると思う。
動いているともっと炎っぽい。
ただ、現状だいぶ重い。
MMX 化することでかなり改善されると思う。
ただ、描画する領域が大きいとそれに従って重くなっていくので、あまり画面サイズが大きいと辛いかも。
ということで、ここから MMX 化による速度改善とテーブルの改善によってよりリアルにしていく予定。
投稿者 Takenori : 00:37 | トラックバック
2008年02月18日
炎エフェクトのクオリティアップと高速化

テクスチャマッピングの実装でミスっていたというか、以前使っていた用途に限定して高速化していたのを忘れていて、そのまま使っていた部分を直した。
後、カラーテーブルも少し改良。
他に風が吹いているように見せたり、最後消火するなど出来るようにした。
で、右側から風が吹いているようにして描画したのが、上の画像。
最初の実装はかなり重く、Core 2 Duo E6750 で 480 x 480 の範囲に炎を描いても処理落ちしていた ( 60 FPS )。
で、これを改善するべく高速化に取り組んだ。
Warp Map のアルゴリズムはまとめると以下のような処理になる。
1. Heat Mapへ火種を描画 (加算合成)
2. Wrap Mapを動かす (バネを模倣した動き)
3. Heat MapへWrap Mapを適用する (テクスチャマッピング)
4. Heat MapへCooling Mapを適用する (減算合成)
5. Heat Mapをぼかす (ガウスブラー)
6. Heat Mapを1ピクセル上へ移動する
7. 描画対象へHeat Mapを適用 (強度に応じた色で塗る)
8. Cooling Mapを1ピクセル上へ移動する
1 ~ 8 を繰り返す。Heat Map はクリアせずに使いまわす。
Heat Map は呼び名がないと不便なので適当に名付けた。仮想的な温度というか濃度というかそういうものを表している。
で、最初はほぼこの通りに実装していた( テクスチャマッピング時に減算合成を同時にしていたが )。
そこで、この 4 ~ 7 のプロセスをまとめ、キャッシュ効率やレジスタ効率を上げることにした。
なお、ガウスブラーは 3x3 で以下の比率でブラーをかけている。
| 1/16 | 1/8 | 1/16 |
| 1/8 | 1/4 | 1/8 |
| 1/16 | 1/8 | 1/16 |
この比率がガウス関数に沿ったものかどうかは知らない。
ガウスブラーは、横方向にブラーをかけたものに縦方向にブラーをかけると、結果的に矩形範囲でブラーをかけたのと同じになるので、1方向で見てみると 1/4、1/2、1/4 を適用すればいいことになるため、効率的なので、上のマトリックスを使っている ( つまり、( 右 + 2 * 中心 + 左 ) / 4 となるため、足し算とシフトだけで計算できる )。
で、いわゆる縦横の for 二重ループ内で 4 ~ 7 を全てやってしまおうとするわけだけど、そのままだとうまく行かない。
横方向ブラーは、1ピクセル遅れ、縦方向ブラーは1ライン遅れで処理していく必要がある。
ただ、縦方向は後でスクロールするから、一番上のラインを処理しても意味はないので、3ライン目以降になる。
ということで、最初の2ラインは減算合成して、1ピクセル遅れで横方向ブラーをかけて書き込んでいく。
3ライン目からは、減算合成して、1ピクセル遅れで横方向ブラーをかけて、上の2ライン分横方向ブラー済みのデータを読み込んで、直前に処理した横方向ブラー後のデータを使って縦方向ブラーをかけて、その結果を使って色テーブルから色を取って来て最終描画対象の1ライン上に書くのとHeat Mapの1ライン上に書き込む。
このようにして出来るだけデータを使いまわして順に処理していくように書き換えた。
これで、MMX など使わなくても 40% ぐらい速くなった。
で、ここから MMX や MMX2、SSE、SSE2 を使って高速化していった。
最初は、この 4 ~ 7 の処理を SIMD 化して高速化した。
横方向ブラーは、単純に直前の8ピクセルと直後の8ピクセルから1ピクセルを得られるようにシフトして、 or を取ったものと、現在の8ピクセルで処理すれば実現できる。
縦方向ブラーは、特に深く考えずに処理できる。
で、SSE2 まで実装してみたところ、MMX2 よりも SSE2 の方が Athlon 64 X2 でも速くなった。
以前のアルファブレンドでは大差なかったが、ある程度の処理を行う場合は、SSE2 の方が効率が良いようだ。
後、シフトと or をとる部分を SSSE3 のアライメント調整命令で実装してみたが、ほんの少ししか速くならなかったので、結局使わないことにした。
次に Wrap Map を動かす部分の高速化に取り掛かった ( 加算合成の部分の SIMD 化はさくっとやった ) 。
プロファイル結果を見るとそれほど処理時間を使っていないが、他の高速化は大変そうなのでやることにした。
ここは 5 x 5 の範囲で 元の位置関係の距離と移動後の位置関係の距離の差に係数をかけた結果を速度に加算して、最後にその速度を位置に加算する処理をする。
元の位置関係の距離は定数となることから元はテーブルで求めていたが、そこを毎回計算するようにしてみた。
つまり、元は len[abs(y-y1)][abs(x-x1)] のようになっていたのを、sqrt( (y-y1)*(y-y1) + (x-x1)*(x-x1) ) とした。
で、計測すると毎回計算する方が速い。
sqrt は比較的重い処理だと良く書いているのだが、abs やテーブルを引く処理の方が遅いのか……
で、次にこの処理の部分をインライン関数化して、24個並べた。
24個並べると、距離は計算する必要がないので、事前に計算した直値をいれる方法に。テーブルを引くのではなく、直接コードに埋め込まれるはず。
これで思っていた以上に速くなった。
速くなりそうだったので、ここを SSE 化した。
SSE 化した時、最初アライメントを気にして処理を分けたのだが、アライメント関係なく読み込む遅い方のを使って分岐しないようにした方が速かった。
やはり、ループ中で分岐するのは遅くなるようだ。
次にテクスチャマッピングの高速化に取り掛かることにした。
テクスチャマッピングの処理が全体の50%を占めているのでここを速く出来れば、かなり高速化できると思うが大幅な高速化は難しい。
続く……
投稿者 Takenori : 00:20 | トラックバック
2008年02月19日
テクスチャマッピングの高速化 その1
現在、テクスチャマッピングは、各スキャンラインで各辺を順に交差判定し、交差したX座標間のUV値を補間しながら描画している。
他のアルゴリズムも試したが、炎エフェクトの描画では使えないことがわかった。
それは、炎エフェクトで使われるテクスチャマッピングでは、凹ポリゴンが含まれているからだ。
この制限がなければ、より高速なアルゴリズムが使える。
とりあえず、今回は使えないことがわかったアルゴリズムは……
最初に試そうとしたのは、各辺のXとUV座標値をY軸値の変化に沿って変化させる方法。
が、初めうまく行かなかった。
で、この方法の考え方を用いて、各スキャンラインで交差判定するが、判定対象の辺を限定する方法を思い付いた。
現在、各頂点は右回りで格納されている。
そのため、頂点番号を-1すると左側へ、+1すると右側へ進む。
また、頂点数は4個なので、 & 0x03 とすれば、判定なしで 0 ~ 4 の範囲を循環する。
このことを利用して、一番上の頂点から、左右の辺を求め、その辺に対して交差判定することで、交差する辺が限定できる。
Y軸値が、辺の下端の値を超えたら次の辺に進めばいい。
また、左右の位置関係もわかっているので、交差判定後にX座標値の大小値を比較してスワップする必要もない。
が、これもうまく行かなくてなぜだろうと思っていて気付いた。
Y軸値は、整数値で変化させているが、この開始値は浮動小数点値からキャストしたものだ。
つまり、切捨てとなっている。
そのため、この整数のY軸値と交差判定しても、交差する辺はない ( 小数点以下が 0 となるまれなケースでは交差するが ) 。
ということで、この整数のY軸値は最初に1加算することにした。
これで、Yの範囲は常に交差するようになり、右方向と左方向へ辺を見て行って判定する方法でうまく行くようになったと思ったのだが…… しばらく動かしているとアクセス違反で落ちた。
なぜ? と思って調べたら、凹ポリゴンだった。
うーん…… この方法で 2% 程度高速化したのだが、この方法は使えないようだ。
( 整数のY軸値を1加算する方法は、1回ループが減るので元のアルゴリズムでも使うことにした )
この+1する必要があるということがわかったので、最初に試そうとしたアルゴリズムを試してみた。
凹ポリゴンが描けないので使えないのはわかっているが、どの程度速くなるか見てみようということで。
アルゴリズムは上述の通り、左右の辺を求めて、その辺でY軸値が1増加するごとにX座標値とUV座標値がいくら増加するか求め、Y軸値が1進むごとにX座標値とUV座標値をその増加値分進めるという方法。
この方法では、交差判定が必要ないので、高速であることが期待出来る。
事実、20% 近く速かった。
でも、今回は使えないんだけど。
ちなみに、最大最小法 + ブレゼンハム でやる方法は、最近の CPU では遅いようだ。
以前、テクスチャマッピングではなく、単純なポリゴン描画で試したことがあるのだが、かなり遅くなったので使わなかった。
これらのアルゴリズムはループ中に分岐を多く含んでいるため、速度が出ないとか。
ライン描画もブレゼンハムではなく、素直に固定小数点でやった方が速いという話も ( 今回のことから考えると浮動小数点でもブレゼンハムより速そう ) 。
このライン描画については一度試してみようと思う。
ライン描画の前にブレゼンハムの考え方を使った拡大縮小を別ので使っているので、そちらでまず試すか。
これを書いていて気付いたけど、凹ポリゴンかどうか判定してアルゴリズムを切り替えると速くなるかもしれないと思った。
ただ、その判定コストに見合うだけ速いのかどうかはわからないが。
後、試したことは……
全て固定小数点で処理するようにしてみたが、逆に遅くなった。
ということで、現在X軸方向が増加する時にUV座標値を増減させる部分のみ固定小数点で処理している。
他に固定小数点にしてMMXやSSE2の倍精度浮動小数点でUV値を同時に処理するなど試してみたが、変換コストの方が大きいのか、遅くなった。
ポリゴン4個同時処理のような並列処理でなければ、速度は出し辛いのかもしれない。
いろいろ試して感じたのは、多少計算量が増えようともループ中の分岐を出来るだけ減らした方が速いということ。
このことを元に、ループ中の分岐を出来るだけ削るなどして、今使っているアルゴリズムでも、4~5%ぐらいは高速化出来た ( ループ中での分岐が1,2個減ることで数%高速になったりする。ループ数が多いところではたぶんもっと効く ) 。
ただ、今のアルゴリズムでこれ以上高速化するのは少し辛い。
もっと別のアプローチで高速化しなければ、速くなったと思うほど高速化することは難しいように思う。
今考えているのは、上に書いたような複数ポリゴンの同時描画。
SSE を使って 4個同時描画に近づける。
炎エフェクトでは、複数ポリゴンで1枚のテクスチャを使う形なので、各スキャンラインである程度絞り込まれた辺と交差判定し、その辺間を補間しながら描画すればいいのではないかと考えている。
各ポリゴンは辺を共有しているので、交差判定後のX座標値やUV座標値の計算量は 1/2+1に減る。
絞り込む処理やまとめて処理することによる速度低下が懸念されるが、計算量ほぼ1/2 + SSE による4個同時処理の恩恵の方が上回ってくれたらいいなぁと思う。
まあ、実際はやってみないとどうなるかわからない。
ちなみに、現在のソースだと 480 x 480 の領域に炎を 60 FPS で描くとしたら、1 ~ 1.5 GHzぐらい必要だと思う。
30 FPS でいいのなら、800 MHz程度でも動くのではないかと思う。
後、領域が狭ければ、劇的に軽くなる。
実際炎を描画するのは画面の一部だろうから、現在でも実用的な範囲に入っていると考えている。
そのうち、Athlon XP 1600 と Pen III 800 MHz でどの程度動くか試してみたい。
投稿者 Takenori : 00:55 | トラックバック
2008年02月21日
テクスチャマッピングの高速化 その2
前回書いたようにポリゴン1個1個描画するのではなく、各スキャンラインでそのスキャンライン上にある全ポリゴンの辺と交差判定するようにしてみた。
その際、8ラインごとにポリゴンの辺と交差するかどうかを保持することにした。
これは頂点が上か下か判定する時に、上から下まで配列にそのポリゴンの辺のインデックスを追加して実現した。
つまり、配列は高さ / 8 個になる。
そして、画像の上から下までスキャンラインを移動させ、辺のインデックスを保持した配列から交差する可能性のある辺を取得して、交差判定後、交差位置を割り出し、1ライン分終わったら、X軸値でソートして、左から順にUV値を補間しつつ描画した。
ポリゴンの辺は、左端にあるものほど先に入りようにしており、X軸値はほぼソート済みとなっている。
そのため、交差する辺の数も少ないことから挿入ソートで実装した ( ソートの有り無しで速度はそれほど変わらなかった ) 。
で、時間を計ってみたのだが、28% も遅い。
交差する辺の絞込み周りがネックになっているようだ。
これを4ラインごとにすると少し速くなるが、1ラインごとにすると遅くなった。
そもそも、交差する辺を判定しなくても良いようにならないものか…… と考えていて気付いた。
スキャンライン基準ではなく、ポリゴンの辺基準でやればいい。
つまり、全ての辺の上端から下端までの範囲に辺のインデックスを格納してしていけばいい。
こうすれば判定は不要になり、そのスキャンラインを通る辺のみが各Y座標値にリストとして得られる。
また、補間に使うY軸値の比も毎スキャンライン計算するのではなく、1.0 / (y2 - y1) で得られた値を加算していけばよくなる。
そして、再度時間を計ってみたのだが、18% 遅い。先ほどと比べると 10% 短縮されているが遅い。
ただ、この方法だと凹ポリゴンをより正確に描ける。
1個1個描画するバージョンは、各辺を順に見ていく関係上凹ポリゴンの時、最初に交差した2辺間を塗ってしまう。
つまり、凹ポリゴンの時、以下の図のように塗られることになる。
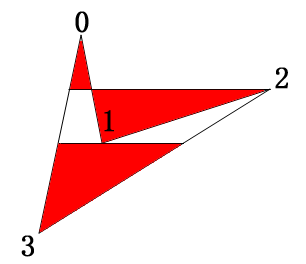
炎の動きが激しくない場合は、それほど凹ポリゴンがないので、気にならないレベルだが、激しくすると破綻しているところが見える。
まあ、普通に使う分にはわからないのだが。
よくよく考えれば、交差位置の計算は必要ないことに気付いた。
前回、右方向、左方向で進めていく方法について書いたが、それと同じように辺ごとに上から少しずつ値を加算していけばいい。
ただ、前回 20% 程度速くなっていたということは、今回の方法でこれを使っても大差ないレベルに出来るというだけの話か。
実際は、テンポラリの変数が増えるのでもっと遅くなりそうか。
この辺りで手を打つかな。
画面全体でやろうとした場合、かなり速い CPU でないと無理そうで、そうなるともう GPU に任せるだろうから。
部分的に適用するものと言う事で使うか。
もっと根本的にリアルタイムで炎を生成せずに、アルファチャンネル付きムービーを実装してしまうと言う手もあるが (笑) 。
投稿者 Takenori : 00:05 | トラックバック
2008年02月25日
テクスチャマッピングの高速化 その3
テクスチャマッピングの高速化を書きつつ、そのアルゴリズムを知らない人にとっては意味不明のエントリーだろうなぁと思って、アルゴリズムについて解説するエントリーでも書こうかなと考えた。
そして、まずは最大最小法だろうなどと考えている時に気付いた。
全ての辺をまとめてやって遅いのなら、1個1個のポリゴンでやればいいのではないか?と思った。
まとめてやると速度が出ないのは、メモリ使用量の増加と間接参照の増加が原因ではないかと思われる。
1個1個やると計算量は 1/2+1 にはならないが、それでも速くできるかもしれない。
基本的なアプローチは一度にやる方法に近い。
まず、左右の X 座標と UV 座標を最初に全て求める。
次に、この間を補間しつつ描画する。
左右の座標を求めるのは、辺が右か左で判断し、2辺目に移った時に、Y座標が上になっていたら、凹ポリゴンか辺が逆に移った可能性がある。
この時、辺が外側に向いていたら凹ポリゴン、内側に向いていたら辺が移ったことになる。
これは下図を参照してもらうとよくわかると思う。
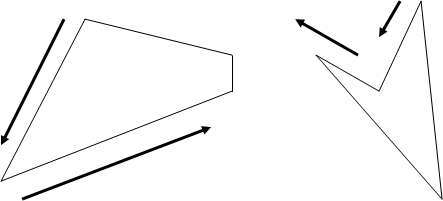
内側か外側かは単純にX軸の値を見ればわかる。
また、間を補間するための値の計算は4つまとめて SSE を使って出来る。
この方法で全スキャンラインで交差判定する方法よりも少し速くなったんだけれど、少し不具合があって時々アクセス違反で落ちる。
Y 軸も X 軸も変化量を加算して求めているために誤差が出ているのか、アルゴリズムに見落としがあるのかわからないが、時々テクスチャ画像の範囲外にアクセスしてしまう。
テクスチャ画像へアクセスする時に範囲チェックをすれば解決するが、それをやると 25% 程度速度が低下するので、かなり遅くなってしまう。
アルゴリズム的な問題は何度か見直したが、解決しない。
どうするかと考え、全スキャンラインで交差判定する方法でも同様に SSE で高速化できるのでは? と思った。
全スキャンラインで交差判定する方法の SSE 化は何度かやろうとしたのだが速度が出なかった。
それは垂直演算に近いことを単に2並列でやろうとしていたからだったのではないかと思う ( U と V を同時に計算しようとするなど ) 。
そうではなく、4 ライン同時に処理すればいいのではないかと思った。
つまり、最初に 4 ライン分の交差判定を済ませ、その後 4 ライン同時に処理する。
また、SSE を使ってスワップやクリッピングを行うので分岐が消える。
実装してみると 9% 程度速度が向上した。
ここからさらに交差判定も SSE 化することでさらに速度向上できるのではないかと思う。
また、横方向の補間も SSE2 を使うことで 4 ライン同時処理出来るので、もしかしたら速くなるかもしれない ( 横方向ラインによって幅が異なるので、終了位置がバラけるのと、テクスチャ画像の参照位置と書き込み位置がバラバラなので、速度が出るかどうかは不透明 ) 。
まだもう少し高速化できそうだ。
投稿者 Takenori : 17:27 | トラックバック
2008年03月01日
炎エフェクトリリースへ向けて……へのはずが
高速化もあまり成果が上がらなくなってきたのと、そろそろ一度リリースしておくかと言うのがあって、公開に向けて整備を開始した。
使う場合は、目標スペックを考えて、描画領域を絞り込んで負荷を抑えることにした。
それでまずは、火種となる画像を複数指定可能にした。
これで、独立に動く火の玉とか、文字を1文字ずつ出して燃やすとかが出来るようになる。
後、描画対象レイヤーのサイズとかバッファが変わっていないか毎サイクルチェックするようにした。
これらを入れると少し遅くなったがそれは仕方ない。
次にパラメータをいろいろ変えても落ちないようにしようとしたのだが……
炎の揺れる速さを上げるとすぐに落ちた。
前々からある程度は認識していたんだけれども……
さらに、あんまり値を上げなくても、かなり長い間動かしていると落ちてしまう。
これはまずいと言うことで調査。
値を上げすぎると、頂点の座標に78億とか入っていた。
これは明らかにまずいので、あまりに大きすぎるか小さすぎる頂点を含む場合は弾くようにした。
後、除数が小さすぎて値が大きくなりすぎることがあるようなので、除数が 0.01未満の時は 0.01 にするようにした。
最終的には、1ピクセルの単位で描画されるので、それ未満の値かどうかによる誤差は気にしないことにする。
これで問題ないかと思ったんだけど、Release 版だけなぜか落ちる。
Debug 版では落ちない。
なんだろう? と思いつつ、Release 版でテクスチャの座標を拾ってくるところで範囲チェックを入れたら、落ちない。
うーん…… やはりここは範囲チェックいるのか。
仕方なく、範囲チェックを入れる。
20% 程度速度が低下した。
困った。
範囲チェックを高速化する方法を考える。
マスクを使おうと思ったが、よく考えたらマスクは二の累乗値幅の時しか使えない。
困った。
二の累乗値幅の時だけ、マスクでチェックするようにした。
このため幅と高さが二の累乗値の時、20% ぐらい速い。
このせいで二の累乗値幅以外では使い辛いかも。
で、範囲チェックがあるんだったら、テクスチャマッピングは毎ライン交差判定する方法ではなくて、稜線に沿って補間していく方法でも問題ない。
確かこっちの方が速かったはず。
と言うことで、次は値のチェックの強化をこちらにも入れて、差し替えてみることにする。
投稿者 Takenori : 19:08 | トラックバック
炎エフェクトプラグイン
吉里吉里2プラグインとして実装した炎エフェクトを吉里吉里2プラグインページに置いた。
サンプルスクリプトと簡単なリファレンス付き。
今のところ動作確認レベルのテストしかしていない。
これから実際にこれを使った演出を組み込んだり、自分が使うパラメータでのテストを行う予定。
ライセンスは、吉里吉里のライセンスと同じ扱いとして、このプラグインを使ってもらってもかまわない。
テクスチャマッピングは結局安全性を優先した方になってる。
自分が使って、パラメータが決まっていて、エフェクトの持続時間が固定なら、結果は同じなのでそれでテストすれば、チェックをそんなに行わなくて速度を優先してもいいんだけど。
投稿者 Takenori : 23:42 | トラックバック
2008年03月03日
炎のをリビルド
Athlon XP の Win2k マシンで確認すると、 C000001D (不正な命令) が発生。
調べると SSE を使っている辺り。
PenIII 866MHz WinXP のマシンでも発生する。
あれかなと思って、コンパイラの拡張命令セットを有効にするでSSE2を使わないようにしたら直った。
このオプションは、使えるか判定せずにSSE2を使うコードを吐いていたのか。
と言うことで、これを外してリビルドしてバイナリを差し替えた。
で、Athlon XP 1600 のマシンで動かすとやはり重い。
60 FPS は出ていない。
でも、なぜか CPU 負荷は 70% 程度。
-contfreq 60 指定が原因の様子。
処理が間に合わない場合は、繰り越しになる作りのようだ。
でも、制限しないと常に CPU を使い切ってしまう。
これは -contfreq 240 などにして回避する手があるとか。なるほど。
速度は ContinuousHandler でコントロールしているので、速いマシンで 240 FPSになることはない。
と言うことで、240 で試すと CPU 負荷は 85% ぐらいで、速くなった。
でも、ContinuousHandler のみで速度制限した物には及ばない。
まあ、その辺りは諦めるかな。
しかし、Athlon XP 1600 では、480 x 480 に 60 FPS で描くのは間に合わなかったか。
Core2Duo の方で制限をなくしてフルスピードでしばらく動かしていたらアクセス違反で落ちた。
あれ?
まだ落ちる可能性があるようだ。
後、現在のはマルチスレッドを切ったのにしているけど、有効にした方がいいかな。
ただ、今のマルチスレッド対応ソースはテクスチャマッピングのところで、上半分、下半分の2つにしているけど、テクスチャマッピングはポリゴン単位でも問題ないので、ポリゴンごとで処理すれば、理論的にはコア数に応じてかなりスケーラブルに速度が上がるはず。
他はマルチスレッド化できなくはないけど、面倒なのでテクスチャマッピングだけしようと思う。
まあ、処理時間の50%以上がテクスチャマッピング関係なので、そこだけでもかなり速くなる。
デュアルコアで今の上半分と下半分で分けたものでは 1.44 倍速ぐらい。
でも、デュアルコアで速くなるとかよりも、もっと低いスペックのマシンで速くならないことにはなぁ。
投稿者 Takenori : 01:32 | トラックバック
炎エフェクトを使えるレベルに
炎のクオリティは問題ない。
思っていたよりも、かなりリアルになってびっくりしたぐらい。
そして、これを組み込んでみるとかっこいい。
でも、重いのを何とかしないと辛い。
最近の CPU なら特に問題ないけど……
Athlon XP 1600 だと、少しゆっくりになっているぐらいで、見れないと言うことはないが……
パラメータの調整で、45FPS ぐらいでも普通に見られるように出来るか。
これぐらいなら要求スペック 1.5 GHzでもいけるかな。
480 x 480 より領域を小さくすれば、だいぶ軽くなるから、範囲をギリギリまで削れば使えるかな。
領域の大きさは、負荷にかなり響く。
小さくすれば劇的に速くなる。
512x512 を 256x256 にするとほぼ4倍速になるので、だいたい大きさに比例している。
でも、大きい領域でも使いたいよなぁ。
それですぐに思いつく方法は2つ。
1. GPU で処理する
2. プリレンダリングする
最終的には GPU で処理するようにしたいが、完全に対応するにはそれなりに時間がかかる。
この炎だけならそれほどでもないと思うが……
GPU で処理して結果を書き戻す手もあるが、それもなぁ。
プリレンダリングして、ムービーでアルファを扱えるようにするのが、比較的早い解決策かな。
他にも融通が利くし。
でも、何かちょっと負けた気がするのが難点か。
投稿者 Takenori : 02:56 | トラックバック
2008年03月06日
炎を入れてあれこれ
Athlon XP 1600 でも 256x256 程度なら余裕なんだな。
常に大きい領域で炎を出すのではなく、表示したい領域を絞り込めば普通に使える。
横幅は火種画像の幅 +32 ぐらいの大きさにして、高さは炎が上に伸びる関係上見ながらある程度調整するか、画面の一番上までとして出す領域を狭めるのが良さそう。
いきなり大きい領域ではじめから処理落ちして遅いと不自然だけど、処理落ちしない小さい領域で炎が出てその後大きく広がるような場合、大きくなった時に急にゆっくりになるが、処理落ちしているのかなとは思うけど、そんなに変ではない。
800x608 ぐらいのサイズだと、2GHzぐらいは必要になりそうだけど、みんなそれぐらいは満たしてないかな? まあ、800x608で炎を出したいがためにそんなスペック要求するのはどうかと言う話だが。
後、倍ぐらい速くなれば、使いやすいのだけれど……
とりあえず、あれからまた 5% 程度高速化できた。
それでもまだまだ重いのだが、実際に組み込んで見た感じでは、別にプリレンダリングにしてしまうほどではないかなと言う感触。
まあ、燃やすもののパターンが結構あるので、プリレンダリングにすると容量食いそうだと言うのもある。
このエフェクトであれば、元々ある絵を火種画像として渡してやれば、その領域を元にして燃えるのでデータ量は増えない ( エフェクト用に特別に火種画像を準備すればその分増えるが ) 。
例えば、立ち絵を火種画像として 0.5 秒ぐらいの間設定しておいて、その後火種画像をクリアすると、一瞬燃え上がるようなエフェクトが出来る。
動いている絵を毎フレーム設定してやれば、それに炎も追従する ( 少し重くなると思うけど ) 。
アルファ付きムービーが使えたら、それを火種画像として設定することで、動いているものに炎を重ねられる ( アルファ付きムービーが使えるのなら、燃えてるムービーをはじめから入れておけと言う話だが )。
で、結局どうするかと言う話だが、単純にオプションでエフェクトのON/OFFを入れればいいやと言う考え。
まあ、できるだけ高速化しようと思っているが。
でも、800x608 の範囲ぐらいなら 1GHz 程度でいけても良さそうなんだけどなぁ。
根拠はないんだけど。
ポリゴン1個ずつやるのではなく、全ポリゴンの辺で一気にやる方法を再び検討する。
凹ポリゴンが少し気になるのと、前やった時に追いつきそうだったこと。
前回はデータ構造がまずかったのではないかと思ったこと。
SSE でスワップが出来るのなら、4つ同時ソートもできるのではないかと言うこと。
きっかけは、プリレンダリングするならできるだけクオリティを高くと思って、凹ポリゴンも綺麗に描画できるアルゴリズムに変えようと考えたことだけど、あれこれ考えてより高速化出来そうだとも思った。
なんとか倍ぐらい速くならないものかなぁ。
炎ではないけど、違うエフェクトを単なる連番静止画で入れてみた。
完全透明領域はカットして、オフセットと静止画像の組で出すように。
で、当然だけれど見た目は普通。
容量はほんの数秒なので、そんなでもない。
アルファムービー入れなくても、今回はこれで十分かと思いつつ、フレーム間差分ぐらい使った方がいいかな? そうすればもっと容量削れる。さらに単純な差分じゃなくて、ある程度動き補償的なものも加えた方が…… と考えていて気付く。
普通に一般的な動画圧縮方法に近づいていることに。
それならはじめから、アルファ付きムービー入れればいいと。
でも、いろいろ工夫して圧縮率を上げるのはそれで楽しいから、惹かれてしまうのだが。
それと、元が自分の作ったスプライトアニメツールで作られているので、アニメ機能入れれば済む話とも思う。
そうすれば、可逆圧縮で最も圧縮率が優れたものになる ( ムービーの圧縮は動画像からアニメーションの元データに近付けようとしているので、アニメのデータが初めからあるのならそれが最も効率的。ただ、効率を考えずに組まれているとその限りではないが )。
先にアニメーション再生機能も入れるかな。
投稿者 Takenori : 03:06 | トラックバック
2008年03月08日
PhotoShop のファイルからレイアウトを取り込む
レイアウトはアニメーションでも表現できるので、全てアニメーションデータとして扱ってしまおうと考えていたが、レイアウトはレイアウトだけで扱えた方が便利なこともある。
と言うか、PhotoShop で組まれたデータをさくさく反映させる方法として、アニメーションデータとは別にレイアウトデータを作ることにした ( 後々考え直して、フォーマットを統一してしまう可能性もあるかも ) 。
それで、レイアウトデータフォーマットをどうするかだけど、いろいろ検討した結果 SVG を使うことにした。
SVG はベクター画像の印象が強いが、単なるラスター画像のレイアウトとしても使える。
ただ、原始フィルタ 'feBlend' では、PhotoShop のサポートする描画モード ( ブレンド方法 ) 全てはカバーできない ( SVG は、normal と multiply、screen、darken、lighten しかない ) 。
たぶん、feColorMatrix や feComponentTransfer、feComposite などを組み合わせたりすることで同じ効果が作り出せるのだとは思うけど、とりあえずはそんな面倒なことはしたくない。
だからと言って、SVG とは違う形にしてしまうのも…… XML なので、拡張して違うネームスペースで定義してしまうと言う方法もあるが、それもなぁと考えていて気付いた。
フィルタは ID を与えて定義し、画像などに対してその ID でフィルタを適用することが出来る。つまり、ID は PhotoShop の描画モードの名前で定義しておいて、SVG にない効果は normal とかにしておけばいいんじゃないか?
これだと SVG 対応のビューアで見た時、描画モードが異なっているので見た目が変わるが、位置などはわかる。
そして、この SVG ファイルを読み込む側では、フィルタがどう定義されているかは気にせず、ID によって識別すれば、本来の描画モードがわかる。
また、将来的に feColorMatrix や feComponentTransfer などを使って SVG ビューアで見た時も同じ見た目になるようにしようとしたときも、フィルタの定義を変えれば済む。
読み込む側は ID でしか見ていないので、そのままでかまわない。
レイアウトデータとして使う側は、SVG の仕様を忠実に守っているわけではないが、忠実に守ろうとしたらかなり面倒な上に、重くなるだろうからそこは気にしないことにする ( なので厳密には SVG フォーマットではない ) 。
と言うことで、このような仕様でツールを作った。
ツールで PSD ファイルを変換すると、レイヤーを PNG ファイルにばらして、配置情報と描画モードをもった SVG ファイルを作ってくれる。
そして、この SVG ファイルは SVG 対応のソフトで見て確認できる ( Firefox に D&D するのが手軽 ) 。
ラスタ化されていないテキストや、調整レイヤー、レイヤー効果などは反映されないので、そのような情報があると明らかに見た目が異なるため、変換してすぐに確認できるのは楽 ( 描画モード全対応でないので、そこでも見た目が変わってしまうが ) 。
これで PhotoShop からレイアウト情報を取り出すことが出来た。
次は、この SVG ファイルを取り込んで、レイアウトデータを反映する方法。
SVG ファイル自体は、XML なので読むのは難しいことではない。
後、上述のように SVG に忠実に対応するのではなく、上の変換ツールで吐き出した SVG のみ読めればいいので、読んだ情報を解釈するのも難しくない。
問題はレイアウトを反映する方法。
SVG ファイル内のレイアウト全てを一度に反映すると言う方法が最初に思い浮かぶが、それでは扱い辛い。
なぜなら、同じレイアウト内に、同時に表示されないものを含むことがあるから。
レイアウトは、他に表示されているものと比べながら行うと思うが、一部分だけ挿し変わるような場合、一度に反映する形だと、ほとんど同じものを2つ作らないといけない。
別にそれでもかまわないが、それは冗長すぎる。
それよりもシンプルで柔軟な形が望ましい。
で、気付いたのが、単純に PhotoShop のレイヤー情報を指定した吉里吉里のレイヤーに反映するだけというもの。
PhotoShop のどのレイヤーかは、SVG にレイヤー名と同じ名前で ID を振ってあるので、それで特定できる。
後、全て反映したい時のために、ID リストを取得できればそれで十分。
つまり、指定レイヤーにレイアウト情報と画像を反映するメソッドと ID リストを取得するメソッドの2つがあれば、それで事足りる。
後はスクリプト側でいろいろやればいい。
それと、反映するメソッドは、オフセットや画像読み込みの有無も指定できた方が良さそうだ ( 他にもいろいろあったほうが便利そう ) 。
レイアウトの情報のみが欲しい時は、一度レイヤーに反映してから取得すれば得られる。
少し回りくどいが、レイアウトの情報のみを欲しいというケースはあまりないと思う。
と言うことで、これからそのようなプラグインを作る。
その後は使いながらイマイチな部分を改善していく予定。
投稿者 Takenori : 16:23 | トラックバック
2008年03月26日
ブラーをもう少し綺麗に
吉里吉里の標準の矩形ブラーは、何か線のようなものが見えるのが少し気になっていたので、もう少し綺麗に見えるものを作ることにした。
ガウシアンブラーだとかなり重いだろうから、1,3,7,3,1 のように2の累乗値ごとに重み付けが変わるようにして作ったが、範囲を大きくしてもなかなかぼやけない。
そこで、もっと単純に 1,2,3,2,1 のように1ずつ大きくなるようにしてみて実装した。
こうするとよりぼけるようになった。
また、矩形ブラーの時のような線は見えない。
今回のを上に標準のを下に描画した時の実行結果は以下のような感じ。
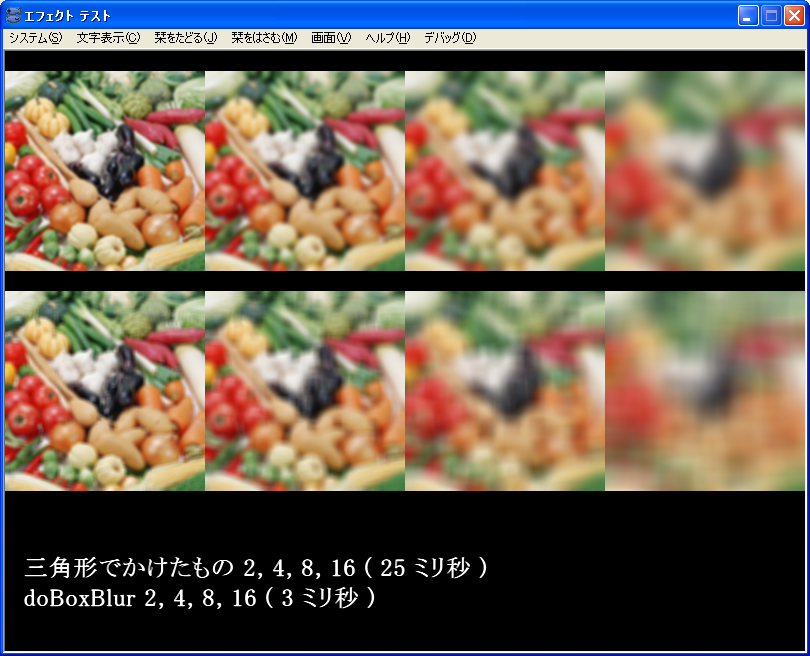
まずまず良好。
が、8 ~ 9 倍遅い。
アルゴリズム的には矩形ブラーと同じような方法を取って速くなるようにしているが、他は特に何も高速化を意識せず書いた。
ここから MMX 化や SSE2 化と、高速化を意識してかけば、倍かそれ以上いけるかな。
すると…… 4倍遅いぐらい?
我慢できるぐらいの速度だろうか?
で、速度計るために複数回ブラーをかけたら、矩形ブラーの変な感じが消えることに気付いた。
なんだ、2回かければよかったのか。
それでも2倍遅い程度だろうからこちらの方が速いだろう。
と言うことで、以下に2回かけた時の比較。
2回かける方法で十分かな。
投稿者 Takenori : 23:07 | トラックバック
2008年03月28日
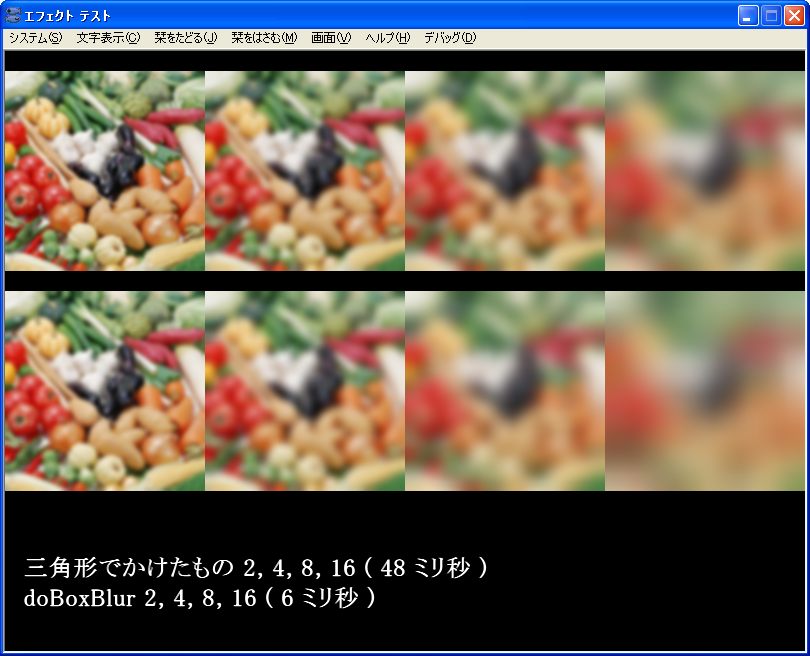
ピラミッドブラーの SSE2 化
ここで作ったブラーを SSE2 化してみることにした。
実装して計って、吉里吉里標準のボックスブラーと比較してみると……
Core2 Duo E6750 で 2.6 ~ 2.7 倍遅い
Athlon64 X2 3800+ で 2.2 ~ 2.3 倍遅い
思ったよりも速い。
Core2 は、SSE2 速いから Core2 の方が差が縮まると予想していたけど、そうはならなかった。
と言うことは、演算速度よりもメモリアクセスの方が問題となっているのだろうか?
MMX 版はまだ作っていないが、この程度の速度差ならボックスブラーを2回かけるのとあまり差はない。
ただ、ピラミッドブラーはボックスブラーと比べて、範囲が広がった時の速度差がボックスブラーよりも大きい。
そのため、範囲を大きくすると差が大きくなる。
上のものは、2, 4, 8, 16 の4パターンを100回かけて計測してた時の速度差。
Core2 Duo E6750 で 範囲を変えて計測すると以下のようになった。
幅 1 の時、2.43
幅 2 の時、2.61
幅 4 の時、2.81
幅 8 の時、2.25
幅 16 の時、2.83
なぜか幅が8の時妙に速い。
品質的には、ボックスブラー2回は2段のピラミッドのようなものと考えられるので、範囲が広がるにつれて差は大きくなると思われる。
でも、あんまり気になるほどではないような。
割る数をループを回さずに計算できないかと調べていて、以下のものを見つけた。
1 = 1 = 1x1
1+2+1 = 4 = 2x2
1+2+3+2+1 = 9 = 3x3
1+2+3+4+3+2+1 = 16 = 4x4
1+2+3+4+5+4+3+2+1 = 25 = 5x5
1+2+3+4+5+6+5+4+3+2+1 = 36 = 6x6
確かピタゴラスの三角形……と思っていたけど、パスカルの三角形だった。しかも、これはパスカルの三角形ではない。
それはともかく、これを使えばループを使わずに計算で求められる。
これで少しだけ速くなった ( 上の計測値はこれが入ったもの ) 。
この程度の速度差なら使ってもいいと思うけど、やっぱりボックスブラー2回で十分。
はじめから2段のピラミッドになるようなものにするのが、それなりに綺麗で速いと言うことになりそうな気がする。
ま、ボックスブラー2回でいいや。
投稿者 Takenori : 00:19 | トラックバック
2008年03月30日
ピラミッドブラーの MMX 化
息抜きに作ってみた。
で、MMX 化する時に気付いたが、幅が15までの時は、16bit 精度で計算できるから、もっと速くなりそう。
と言うか、MMX の場合掛け算が 15bit 精度 (+符号) になってしまうので気付いた。
MMX2 なら符号なしが使えるので 16bit 。
つまり、MMX 版は幅 10 まで ( 掛け算の時に int に戻してきてやればもっといけるが ) 。
使おうと思っている用途では、そんなにぼやけさせないので、10 もあれば十分。
たぶん、3 か 4 程度で使う。
まあ、それはいいとして、16bit で MMX2 で実装し、2, 4, 8, 15 の4パターンを100回で計測したところ、1.93 倍程度になった。
それと、幅が小さい時だけ計ってみた。
幅 1 の時、1.42 倍
幅 2 の時、1.60 倍
幅 3 の時、1.78 倍
幅 4 の時、1.92 倍
Athlon64 X2 3800+ で 2, 4, 8, 15 の4パターンを100回は 1.55倍程度。
幅が10までなら、ボックスブラー2回かけるよりも速くなった ( 計ってみると幅が11で2倍を超えた ) 。
と言うことは、SSE2 版で 16bit 精度のを作れば、もっと速くなりそうだな。
使えそうになったな。
追記:
と思ったら、アルファ考慮していなかった。
不透明なら今の方法でもいいが、違う場合はアルファをかけないといけない。
だから、もう少し遅くなりそう。
投稿者 Takenori : 03:53 | トラックバック
2008年04月15日
SQLite3 の XP3 用 VFS
SQLite の VFS や xp3_vfs で書いた、SQLite3 の XP3 用 VFS をコミットした。
これを使えばアーカイブの中に SQLite の DB を入れておいて、クエリー発行してそのデータベースファイルからデータが読める。
アーカイブの外にあってもいいんだけど、やっぱり中に入れておきたい。
これを使うにはプラグインを作る必要がある。と言うか、プラグインを作るためのソース。
汎用的な SQLite 3 のプラグインは作っていない。
特化して作ったものは、その用途であれば使えるので、これもついでに入れておこうかと思ったが、よく見たら、テーブル名などが汎用的な名前じゃなかったので止めた。
O/Rマップで使える汎用的な SQLite 3 プラグインは気が向いたら作るかもしれない。
TJS2 のクラスや Dictionary で SQL をあまり意識せずデータを出し入れできれば、データ保存などで便利なはず。
投稿者 Takenori : 01:25 | トラックバック
framemove タグ
KAG の move タグは、一定時間間隔ごとの位置と不透明度を指定してアニメーションさせるタグだけど、これはどうも使い辛い。
指定した時間に指定した位置と不透明度を設定して、アニメーションさせる方がやりやすいはずなので、そういうのを作ろうかなぁと前々から思っていて、作ったのでコミットした。
次のリリースには framemove タグが入っているのではないかと思う。
具体的な使い方や説明は以下のような感じ。
使用例
[image storage="bg" page=fore layer=0 opacity=0 left=0 top=0 visible=true]
[image storage="uni" page=fore layer=1 opacity=255 left=50 top=50 visible=true key=adapt]
[framemove path="(30,0,0,255) (60,0,0,255) (120,0,0,0) (130,0,0,255)" layer=0 page=fore fps=60]
[framemove path="(10,0,0,255) (100,400,400,255) (130,0,0,255)" layer=1 page=fore fps=60 ox=50 oy=50]
[wm][wm]
layer, path 必須
path
(frame, left, top, opacity) の順で指定する
frameは、1以上の値を指定すること
0フレームは現在のレイヤー位置と不透明度になる
fps はフレームの再生速度
1/fps 秒が 1フレーム辺りの表示時間。
描画周期は、ContinuousHandler の呼び出し頻度に依存する。
省略時 30fps になる
oxは、X軸のオフセット値。
oyは、Y軸のオフセット値。
基点は異なるが、同じ動きをさせたい時など、マクロ化してオフセット値のみを変える事で同じ動きをさせることが出来る。
省略時 0になる。
シンプルな動作であればこれで十分なはず。
やろうと思えば、ある程度複雑な動きも出来る。
拡大縮小・反転・回転などはないので出来ない。
複雑な動きをさせるためには、拡大縮小・反転・回転・ブラーなどの現在の状態と現在の画像、元データ画像を持ったものを作ったほうが良さそう。
で、状態が変更された時に現在の画像を変更するような。
投稿者 Takenori : 01:36 | トラックバック
炎エフェクトの高速化 全辺一気版
炎を入れてあれこれに書いたように、再検討した全ポリゴンの辺で一気にやる方法を試してみることにした。
まずは SSE を使用せずに実装して、測ってみる。
SSE を使わない版の前のと比べると 8.5% 程度速い。
やはり、アルゴリズム的にはこちらの方が速いのかな。
交差判定がなくなっている代わりに、保持する途中のデータが増えているので、速いかどうかわからなかったが。
でも、問題は SSE 版。
SSE を使って速くないと意味がない。
今、SSE を使うバージョンを実装中。
それにして、SSE 版を作るのとか飽きてきた。
基本的には同じ処理をする関数を別に作ることになるので余計に疲れる。
もうちょっとうまい具合に出来ればいいんだけどなぁ。
投稿者 Takenori : 01:40 | トラックバック
炎エフェクトの高速化 全辺一気SSE版
全辺一気にやる方法をSSE化してみた。
結果、1.5% 速くなった。
うーん、大幅に変えた割には大して速くならなかった。
と言うか、そもそもテクスチャマッピングの補間部分はあまり処理時間を使っていないのかもしれないと、いくつか処理をコメントアウトして時間を計ってみた。
前にテクスチャマッピング処理自体をコメントアウトして計ったら、75% ぐらいの時間がテクスチャマッピングに使われているようだった。
今回、元データを読み込んで、書き込む部分をコメントアウトしてみたら…… 全体の 58% の時間がここで使われている。
さらに、書き込み値を固定値にして、読み込み部分をコメントアウトしたら、全体の 46% の時間がここで使われている。
つまり、データを読み込む部分に 46% の処理時間がかかっていることになる。
やっぱりテクスチャマッピングの補間部分はあんまり時間使っていないようだ。
処理時間でどこでどれだけ使われているかまとめてみると……
12% ピクセル書き込み ( テクスチャマッピング )
46% ピクセル読み込み ( テクスチャマッピン グ)
17% テクスチャマッピング残り
25% そのほかの処理 ( ブラーとかWarp Map動かしたりとか最終的な色を書き込んだりとか )
そのほかの処理はかなりいろいろやっている割に速い。
補間処理部分はそれなりか。
と言うか、ピクセル読み込み ( メモリ位置を求めたりするのも含む ) 遅い。
ここを攻めるべきだな。
今、最初に画像サイズのメモリを確保した後、縦方向の開始アドレスの配列を別に作って、2次元配列としてアクセスできるようにしている。
これを補間の段階で1次元配列としてアクセスすれば、速くなるのではないかということで試してみた。
ΔU、ΔV をまとめして処理できるようにと考えたが、これはうまくいかないようだ。
よく考えたら当然か。
そこで、x と y でアクセスしていたのを y * stride + x としてアクセスするようにした。
その際、範囲チェックは index < range として、配列の範囲ないなら値を読み出し、範囲外の時は0にすることにした。
で、動かしてみると…… 19% 程度高速化された。
速い。
後、前はしばらく動かしていたら落ちていたけど、この処理にしたら落ちなくなった。
バイリニア補間の時はまた別に関数を作らないといけないけど、この方法で行くかな。
ただ、横端の方で範囲外になると折り返されて表示されてしまうはずなので、端の方にも炎を表示する時は気を付けないと変になると思う。
Core 2 Duo E6750 ( 2.66GHz ) で 512 x 512 の範囲に描いたとして、CPU 負荷はコア1個で 14.3% 程度。
Athlon 64 X2 3800+ ( 2GHz ) で 38%程度。
Athlon XP 1600+ ( 1.4GHz ) で 71%程度。
なお、ここでの値は炎の処理のみで、この後吉里吉里の合成処理分の負荷が追加される。
で、見た目では Athlon XP 1600+ は少し遅いように感じるが、それほどではない。
何とか使えるぐらいかな。
凹ポリゴンもきちんと描画して、落ちなくなって、2の累乗値の制限もなくなって、20%程度高速化されたので、前よりもだいぶ使えるようになったはず。
後はソースコードを整理して、SSE版と非SSE版を分離して、もう少し最適化出来そうならしてみる。
その後、公開しているのを差し替えよう。
そしたら、炎は完成として、しばらくいじらないかな。
投稿者 Takenori : 23:22 | トラックバック
2008年04月16日
炎エフェクトプラグイン リリース2
前回 のを更新。
1個だけメソッド名が変わってます。
updateWrapMap を updateWarpMap に変更しました。
WrapMap ( ラップマップ ) だと思っていたら、WarpMap ( ワープマップ ) が正解だったので、それに合わせて名前変更しました。
最初に見間違いをしていた様子。
他の変更点は、
20% 程度高速化された。
2の累乗値の時速いとかはなくなり、サイズが小さいほど速い。
ぐらい。
領域の幅と高さが16の倍数にするのは残ってる。
1.5 GHz 程度で 512x512 の範囲ならそれなりに動く。
もっと範囲が小さくなれば余裕。
そう言えば、SSE のない CPU 持ってないから、非 SSE 版が SSE の付いてないCPUで意図したとおりに動くかどうかはテストしていない。
SSE を使わないバージョンが動くことは確認したけど。
まあ、そもそも Pentium III や Athlon XP以降でないとまともに動かないと思うが。
投稿者 Takenori : 18:05 | トラックバック
2008年05月12日
ゲームパッド プラグインがとりあえず動くように
DirectInput と XInput に対応し、複数パッドを扱えて、フォースフィードバックのバイブレーション対応、アナログスティック対応したゲームパッド プラグインがとりあえず動くようになった。
XInput デバイス ( XBox360 コントローラ) と DirectInput デバイスをつなげて、両方のパッドからアナログスティックの情報を得られることを確認。
アナログスティックは、-1.0 ~ 1.0 の値を返すようにしている。
細かい部分のデバッグとボタン設定用のインターフェイスはまだ。
DirectInput デバイスはパッドによってボタン配置が違うので、設定用のメソッドは必須だろう。
アクション マッパーは使わない予定。
XInput デバイスはボタン固定なので、ボタン設定用のメソッドは持たない。
このプラグインでは、あくまでパッド間の差異を吸収するための設定と考えている。
でも、そしたらゲーム個別の設定が出来るようにしようとしたら、2回も設定が必要か……
その辺りは少し考えないとダメかな。
投稿者 Takenori : 23:33 | トラックバック
2008年05月13日
ボタンエッジ検出と長押し判定
今作っているゲームパッドプラグインでは、単純に現在のボタンやキーの状態を取得するのみになっている( 厳密には、パッドの update メソッドをコールした時の状態 )。
この機能のみあれば、スクリプトでエッジ検出や長押し判定することが出来る。
ただ、エッジ検出や長押し判定は、よく使うと思うので、プラグイン内に入れてしまってもいいかもしれないと考え中。
update がコールされた時、対象のボタンが押されていれば 1加算、離された時 ( 押されておらず値が 0 より大きい時 ) -1 に、押されていない時 ( 値が 0 以下の時 ) は 0 にする。
このようにすれば、0 より大きい時は押されていて、0 以下の時は離されているのがわかる。
また、マイナスの時は離された瞬間、1 の時は押された瞬間とわかる。
長押しは、どれぐらいの長さにするかによるが、値がいくつ以上かと判定することでわかる。
仕組み的にはこんな感じで。
もっといい方法があれば…… と考えていた気付いたけど、長い間押されていないのも判定できた方が良いだろうか?
単純に 負の値の時に 1 減算していくことで、どれくらい長い間押されていないかはわかる。
しばらく操作されていないとキャラクターがあくびするなどの時に使う…… ことはないか。
操作されていないのであれば、全ボタンで判定した方が効率的。
まあ、長押されてない判定もあってもいいかな。
あって不都合はないし。
ボタンエッジ検出や長押し判定は、状態取得のクラスに入れるのではなく、そのクラスをラップして実現するのがいいかな。
ゲームパッドの状態取得クラスは、IInputDevice インターフェイスを継承して作っている。
これの派生クラスは、XInput 用、DirectInput 用、DirectInput フォースフィードバック対応用の3つある。
継承関係の間に入れるという手もあるけれど、必ずしもボタンエッジ検出や長押し判定が必要とは限らないので、包含して拡張するのが良いかな。
ま、ボタンエッジ検出と長押し判定は入れよう。
いずれかのボタンが押されている離されているも。
投稿者 Takenori : 15:58 | トラックバック
2008年05月28日
プレイ画面の動画書き出し
前々から動画の書き出し機能があると便利かなぁと思いつつも、需要があるのかどうかわからなかったので、特に手をつけていなかったんだけど、ある程度は使う人がいそうなのと、自分も使いそうなので作ることにした。
AVI で書き出すものはごうさんが既に作っていたけれど、AVI 2.0未対応で無圧縮で保存されるので、あっという間に2GB超え&HDDへの書き出しが間に合ってなさげで、扱いづらかった。
そこで、AVI 2.0 対応のために DirectShow を使用して書き出すことを考えていたが面倒くさい。
あれこれ考えていて、ふと、WMV で書き出すものなら、さくっと出来る気がした。
という事で、コーディング開始。
さくっと…… と思ったけど、4時間ぐらいコーディングにかかった。
動画系の API は手続きが多いので、いろいろと面倒だった。
改めて考えると、DirectShow を使っても大差なかった気がする。
で、動かすと IWMWriter::BeginWriting でエラーが返ってくる。
内容は、Video codec エラー ( An unexpected error occurred with the video codec ) 。
さっぱり理由がわからない。
サンプルのソースといろいろ見比べたり、サンプルをデバッガで動かして入っている値を見たりして修正するも改善せず。
もしかして、スレッドを分離しているのが原因? と思って、IWMWriter::BeginWriting を初期化側のスレッドとあわせるとエラーにならなくなった。
別スレッドにしたらだめだったのか。
でも、実際の書き出し部分はスレッドが分かれていても問題ない様子。
バッググラウンドでひたすらエンコードしてもらう必要があるので、書き出し部分は別スレッドに出来ないと少し面倒なので、そこは良かった。
という事で、吉里吉里でゲーム画面の動画を書き出すプラグインを作った (結局1日かかった)。
が、ここではまだ音に対応していない。
吉里吉里の本体から直接音を得る方法はない様子。
本体をいじるか、ループバックで録音するか。
結局、ループバックで録音する方法で行くことにした。
エラー音やクリック音などが鳴ると、一緒に録音されてしまうという難点があるが、まあそこは諦めるという事で。
音のキャプチャー自体は、DirectShow を用いて行った。
ここは特に問題なかったのだが、WMV 書き出しでまたうまく行かない。
エンコードしていたら途中で落ちてしまう。
エラーは The writer has received samples whose presentation times differ by an amount greater than the maximum synchronization tolerance. You can set the synchronization tolerance by calling IWMWriterAdvanced::SetSyncTolerance. とか。
IWMWriterAdvanced::SetSyncTolerance で時間を長くすると、どんどんメモリに溜めていってなかなかエンコードしない様子。
で、終わったものをみてもうまく撮れていない。
なんなんだろう? といろいろと調べていたら、書き出し時に指定するストリーム番号が設定されていなかった……
絵だけや音だけの場合、そこがおかしくても問題ないけど、絵と音のように2つ以上ストリームがある場合はまずいようだ。
というか、設定する部分を見逃していた。
これで音も撮れるようになった。
結局2日かかった。
ただ、これには問題がある。
WMV をリアルタイムでエンコードする関係上、すごくCPUパワーが必要。
640x480 30FPS では、Core 2 Duo E6750 (2.66GHz)、メモリ 4G、HDD RAID 0 でも間に合わない。
動きの少ないシーンでは大丈夫のようだが、動画を再生しながらとなるとだめ。
エンコードが間に合わない場合、メモリ上にひたすら画像を溜めていくのんだけど、どうも吉里吉里側の描画の方が処理落ちして、それであんまりメモリには溜まらずに進んでいく様子。
プライオリティーをいじれば解決するかもしれないけど、4Gあっても1分程度しか撮れないのであまり効果はない。
これはクアッドコア必須か。
ただ、Video Codec を Windows Media Video V7 や V8 にすると負荷が下がり撮れる。
というか、マルチスレッド化されておらず片方のコアをめいっぱい使っているだけのように見えるが、撮れることは撮れている様子。
まあ、これでいいかなぁと思ったが、もっと速い CPU が欲しいと自分も周りもつぶやいていて、少し考える。
連番 JPEG 書き出しバージョンを作ろう!
JPEG エンコードは、SIMD 拡張版 IJG JPEG library を使う。
で、組む。
1時間ぐらいで出来た。
WAV でもいいから音入らない? と言われる。
で、組む。
さらに1時間ぐらいで出来た。
いい感じ。
Core 2 Duo E6750 (2.66GHz) で CPU 負荷が 20 ~ 30% 程度。
比較的軽い。
WMV よりも容量が大きくなってしまうのは仕方ないが、バラバラのファイルになるので HDD 容量のみの問題だから、容量が大きくなるのはそれほど問題ではない。
実際のゲーム画面がキャプチャーされたものを見る。
普通に見れる。
というか、ゲームじゃなくてこっちでもいいとか思ったり。
それはどうか…… と言う話なんだけど、字幕付きのアニメを見ている感覚で楽。
これはちょっと考えさせられた。
このプラグインは少し使い方が厄介なので、マニュアルを少し書かないといけない。
その辺り書けたら公開するかも。
投稿者 Takenori : 13:31 | コメント (4) | トラックバック
吉里吉里2 + キャプチャープラグイン = 動画作成環境
吉里吉里2 と キャプチャープラグイン の組み合わせが、動画作成環境としてかなり高機能な気がする。
という事で、ゲーム画面動画キャプチャープラグインをリリース。
このページに置いておきます。
投稿者 Takenori : 16:10 | トラックバック
2010年01月30日
炎エフェクトプラグインサンプル動画
WMV 出力プラグインを作ったと言うことで、上げてみる。
WMV 出力プラグインは、今のところ音未対応。
吉里吉里のレイヤーを順に渡していくことで動画が出来る。
投稿者 Takenori : 18:36 | トラックバック
2010年04月17日
スクリプトデバッガー
先週の土曜日 ( ちょうど一週間前 ) からスクリプト言語用のソースレベルデバッガを作っている。
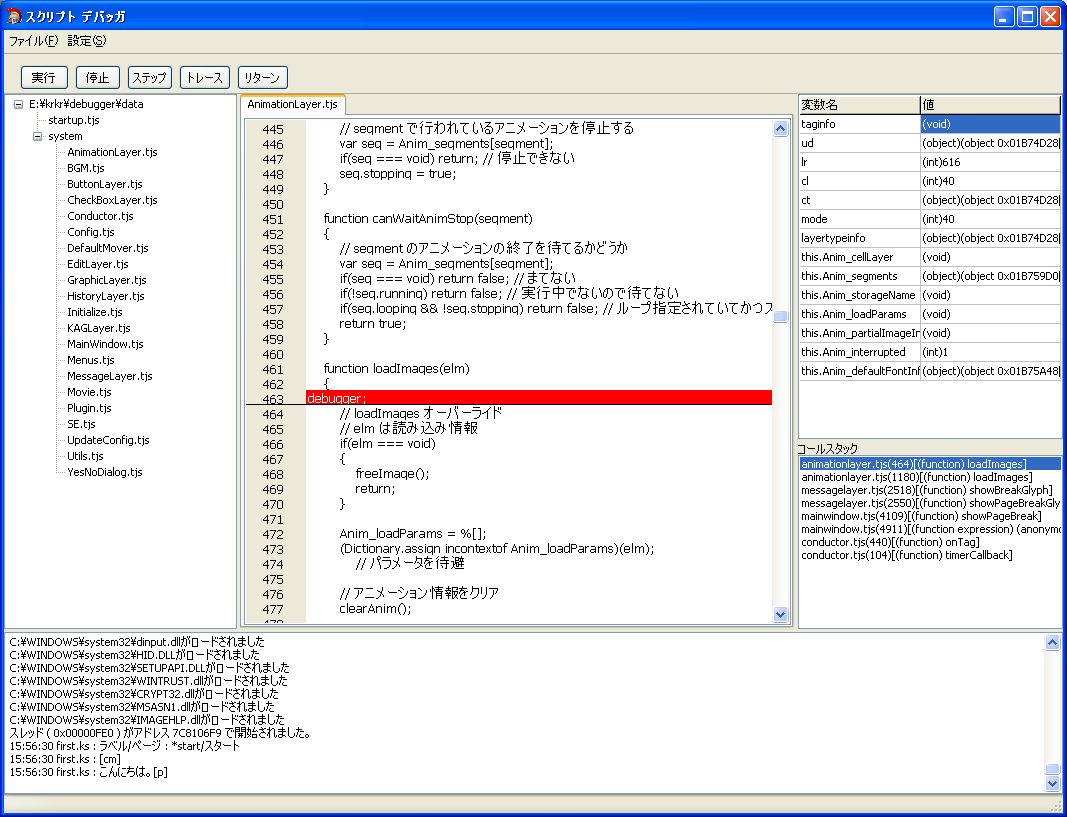
ネイティブなデバッガの場合、ブレークポイントはコードを書き換えて、ブレークポイント例外を発生させる命令に置き換えるので、スクリプトの場合も同じようにバイトコードを書き換えてやればいいのかなぁと漠然と考えていたんだけど、Squirrel のデバッグ用 API を見てそんな面倒なことしなくてもいいことに気付いた。
基本的な API は単純で以下のようなコールバック関数を登録できる。
debughook( event_type, sourcefile, line, funcname )
event_type は、各行の実行時、関数の呼び出し時、関数の終了時 の3種。
この API を見た瞬間どうすればいいのかわかる。
ブレークポイントで止めたければ、sourcefile と line を見て、ブレークポイントが設定されているものと同じであれば止めればよい。
ステップ実行は、各行の実行時ごとに止め、関数呼び出しなどが発生した場合は、ネストをカウントして、リターン時に減算、元の深さに戻ってきたら、またステップを進めればよい。
トレース実行はさらに簡単で、3種のイベントどれでも止めてしまえばよい。
ブレークやステップ実行はこれで楽勝。
と言うこととで、吉里吉里2のソースを追って同じようなコールバック関数を登録できるようにする。
これをプラグイン用に公開…… と作っていたんだけど、本体の方に手を入れまくるんだから、わざわざプラグインにする意味はないかと本体に組み込んでしまった。
そして、固定位置にブレークポイントを置いて正しく機能するか確認。
ファイル名と行番号で行が切り替るごとに判定すると言うやや力業な方法なので、負荷増が気になっていたが気にするほどでもなかった。
まあ、画像等に比べればテキスト処理で負荷が気になることは変なことしなければあまりないか。
そんなに遅いマシンを開発用に使っていることはあまりないだろうし。
デバッガとデバッギ(吉里吉里2)は、扱いやすさを考えて別プロセス(アプリ)で作ると決めていた。
作るのは同じプロセスの方が簡単だけれど、そのプロセスが終了するごとに設定とかいろいろとやり直しになるのは面倒この上ない。
普通のデバッガのように「実行」ってしたら起動して動いて欲しい。
そのようにするためには、プロセス間で通信する必要がある。
はじめはお互いにイベントを投げ合えばそれでいいと考え、そのように実装したがすぐに問題に気付く。
吉里吉里2は、メインのメッセージループが回るよりも先にスクリプトが実行される。
でも、そんなこと気にせずメッセージを取得しようと試みたが、どうもうまく受信できない。
と言うことで、早々にこの通信方法はあきらめる。
この方法には他にも問題があると認識していたのもある。
その問題とは、停止していると言ってもメッセージループは回しているので、別スレッドは動いている。
つまり、サウンドやムービーが停止中も進んで行ってしまう。
これは、余り好ましくない。
通信関係よりも前に、面倒が起きないように、デバッグ対象のプロセスを、デバッグ用に起動して、デバッグイベントを受け取るようにしていたので、デバッギでブレークポイント例外を発生させて止めて、その後何かを使って要求を送れば解決できる。
要求とは、ステップ実行などの種類やブレークポイントの位置。
ブレークポイントかどうかはデバッギ側が判断するので、デバッギに送ってやる必要がある。
が、停止しているプロセスにどうやって要求を送るのか? が問題。
Windows のデバッグ用API にはデバッグ対象プロセスのメモリを読み書き出来るので、これを使うのが本節だろうけど、どうやってアドレスを得るのか?
いろいろ考えた結果、デバッギ側に通信用のメモリをあらかじめ確保しておいて、それをデバッガ側に伝えてもらって、以降はそのアドレスに書き込んで通信することにした。
デバッギ側からデバッガ側への通信は普通にメッセージで送れるので、そのようにした。
どこで停止したかやコールスタック、変数の情報などもメッセージで送ってしまう。
メモリが読み書き出来るので、頑張ればたどれるけど大変なのでデバッギ側に教えもらう。
これで後は作り込めばOK
ただ、吉里吉里2ソースを追って、ローカル変数の取得方法やメンバ変数の取得方法などを調べて、取得のための機能を追加するなどが大変だった。
吉里吉里2は、コンパイルが終わるとローカル変数の名前は破棄してしまっていて、レジスタしかわからない。
だから、名前とレジスタ、スコープを記憶して、現在のスコープの変数とそのレジスタ位置から値を得なければいけない。
スコープの単位は、ブロックごとにしてもいいけどそこまでしなくても関数単位で十分なので、そのようにした。
スコープは、クラス名、関数名、ファイル名、バイトコードオフセットで判断。
クラス名等の名前は、ユニークなIDになるようにして保持。
ソースにするとこんな感じ。
struct ScopeKey { int classindex_, funcindex_, fileindex_, codeoffset_; };
このキーをmapに入れて、その値に変数のリストを入れる。
operator < の判定は、classindex_、funcindex_、fileindex_、codeoffset_ の順。
つまり、内部的にはクラス順、クラス内は関数順…… と並ぶ。
ScopeKey を使ってそのローカル変数を取り出すことは普通に出来る(そもそもそれが目的)し、クラスの中の全ローカル変数や、関数の中のローカル変数を取得することも出来なくはない。
不要だけれども。
まあ、クラスのメンバ変数を funcindex_ に -2 を入れて……等のルールを決めれば、これでクラスのメンバ変数も管理できるが、別管理で実装した。
後、スコープをブロック単位で管理しようとしたら、codeoffset_ をブロックごとに持てばよい。
上位ブロックの変数を得ようと思えば…… ってダメじゃん。
この管理構造で対応出来ると思っていたけど、欠陥に気付いた。
まあ、関数単位で管理することにしたからいいか。
ScopeKey はなかなかいい思いつきと思ったけど、全然そんなこと無かった。
話が大きくそれたけれど、基本機能はこれでほとんど実装できた。
残りは使いやすくするためのデバッガの細かい機能類。
TJS2 対応のデバッガが一段落したら、Squirrel に対応する予定。
PC 上の別プロセスのみでなく、リモートというか、ゲーム機のスクリプトのデバッグに対応して、しばらくはそれメインに使うはず。
スクリプトでもデバッガが使えると便利だろうなぁ、欲しいなぁと常々思っていたけれど、実装に動いているのを見るとかなり便利そう。
スクリプトのデバッグは、修正の容易さと記述能力の高さに頼って printf デバッグが基本だったけれど、デバッガで処理の流れを追えるとどう動いているのかわかりやすい。
しかし、これはいいなぁ。
普通に売れるよね? 自分だったら売ってたら買う。とか思ってしまう(吉里吉里用は普通にフリーで公開予定)。
スクリプトデバッガ自体は、比較的汎用的に作っているので、他の環境へのポーティングもそう大変ではないはずなので、他の環境で作る用になった時は、まずはこれをポーティングして…… となりそうだ。
投稿者 Takenori : 17:38 | コメント (5) | トラックバック
2010年08月09日
スクリプトデバッガーコミット
先週にデバッガで動くようにした修正とデバッガをマージしてコミットした。
ただ、そのままのビルドでは有効にならずデバッグオプション「ENABLE_DEBUGGER」を付けてコアをビルドしたら有効になる。
デバッガ機能が有効になった場合でもデバッガ用のデバッグ機能はデバッガからコアが起動された場合のみ有効となる。
デバッガ本体のソースもコミットしている。
現状は、使える程度であまり便利ではない。
この辺りは、実際に TJS2 でゴリゴリ何かのシステムを書いていく時に改良していこうと思っている。
スクリプトだとデバッガがないことは多いので、そう言うもんだと思ってひたすら print とかして作ってたけど、デバッガがあるとやっぱり便利。
TJS2 での開発中は常にデバッガ経由での起動になりそう。
今のところすぐに TJS2 で何かの開発にと取掛かることはないんだけど。
投稿者 Takenori : 14:27 | トラックバック
2012年04月26日
気になる挙動を調べてみた
tjs2では特定条件で判定からはずしたブロックのdeleteが実行されるらしい? ここに記述されている内容が気になったので調べてみた。
以下スクリプトと問題点を転記。
|
function test() |
dm("■lay:"+lay); で、lay がないと言われて例外発生。
|
function test() |
このように記述すると問題なく動作する。
|
function test() |
dm(p); での p の値が不定。
3個目の変数アクセスの方は比較的簡単。
中かっこのない if 文はスコープをネストしないので、var で変数宣言したら上位のスコープと思えるスコープに変数が作られる。
で、dm でアクセスした時、変数はあるが初期化されていないので、未初期化変数へのアクセスとなり、値は不定。
1個目の挙動は少しやっかい。
バイトコードを出してみると、delete は通らないし、デバッガで追ってみても通らない ( そもそも delete のコードは出力されない ) 。
例外が発生するのは、dm("■lay:"+lay); で lay へのアクセスが、proxy(this or global) のメンバ lay へアクセスしようとしてメンバが見付からないところ。
なぜここでローカル変数へのアクセスではなく、メンバアクセスになっているか。
ローカル変数に対する delete がどのようになっているかを調べると、処理はコンパイル時に行われていた。
ローカル変数に対する delete のバイトコードを作るところで、ローカル変数の lay が削除されてしまうので、dm("■lay:"+lay); ではローカル変数の lay は消えているため、メンバアクセスになっている。
そして、これはコンパイル時に行われるため、if 文は関係なく、単純に前にあるか後ろにあるかによって変数があったり、なくなったりする。
2個目がなぜ通るのかと言うと、上述の処理を見ればわかる。
if 文のスコープ内にある lay 変数は削除されるが、それより外のスコープの lay は削除されず、ローカル変数へのアクセスとして解釈されて、期待通りの動作をするはず。
これは実際に処理を追ってないのである程度推測。
動作はいいとして、ローカル変数への delete はこのような仕様であると認識して使わないと意図しない記述をしてしまいそう。
と言うか、ローカル変数を delete すること自体が問題の種か。
まあ、ローカル変数を delete しようとした事はないが。
中かっこのない if 文の方は、そんなことしないから気にする必要ないと思うけど。
投稿者 Takenori : 22:57 | トラックバック
2012年06月26日
デバッガ有効版
ふと思い立って吉里吉里2 デバッガ有効ビルド版+デバッガ をビルドして置いた。
ビルドは今日の SVN 上のソースで ENABLE_DEBUGGER を有効にしたもの。
W.Dee さんは、同梱する事も検討しているようなので、同梱されるようになったら意味がないので削除する。
投稿者 Takenori : 20:05 | トラックバック
2012年11月29日
パーティクル
パーティクルが使えると何かと便利なので作っていた。
パラメータが多くて面倒だったけど、なんとか絵が出るところまで来た。
絵が出るようになると俄然楽しくなってくる。
ソフトウェア描画であまり最適化していないので重い。
対応できていないパラメータや細部の動作など作ったら最適化する。
投稿者 Takenori : 02:28 | トラックバック
2012年12月12日
pee ( Particle Effect Editor)ベータ版
とりあえずベータ版を公開。
pee ( Particle Effect Editor)ベータ版
ベータ版なので不具合等あると思います。
ざっくり使い方を説明した動画。
演算誤差か何かで少し変な黒い線画出てしまっている部分がある。
後、背景への重ね合わせ部分が通常のアルファブレンドになっているため、少し印象の違う結果になっている部分もある。
加算系のときは、レイヤーも加算指定にすればいいが、背景が明るいと飽和して変な色になるから、通常のアルファブレンドの方が良い結果になることもある。
後は吉里吉里用のプラグインと高速化、テスト&不具合修正などしたら完成。
ノベルゲームで使うことを考慮したパラメータ構成になっていると思うけど、足りなさそうならまた考える。
プリセットがあれば呼ぶだけでさくさくエフェクトを追加できて、画面に動きが出るように。
他のパーティクル系ソフトとアルファチャンネル付き動画を組み合わせることで同じことが出来るけど、動画だと容量が大きくなるという難点があった。
これだと小さいテクスチャとパラメータファイルだけで済む。
投稿者 Takenori : 04:30 | トラックバック
2012年12月16日
パーティクルプラグイン
吉里吉里2プラグインページに開発中のバージョンのものを足しておいた。
でも、pee が今起動できなくなっているか。
後、FlyFishLite ( スプライトアニメーションツール ) を暫定公開。
投稿者 Takenori : 02:24 | トラックバック
2012年12月17日
pee 更新
pee ( Particle Effect Editor)ベータ版
ファイル読込みとSSE2の対応を行って更新。
後はデバッグと高速化、ドキュメント整備。
更新したので、使用日数制限が消えてまた使えるようになっています。
これでプラグインを使って実際に吉里吉里2上で動かして試すことが出来ます。
投稿者 Takenori : 05:07 | トラックバック
2012年12月18日
パーティクル描画順
パーティクル描画順の問題は前から認識していたけど、そんなに気にならないかなとも思っていたら、作るものによっては厳しいことに。
キャラのバックでわーっと出るとかあるだろうと思って作ってみたら、中心付近がかなり見づらいことに。
何らかのソートはやはり必要そう。
後、右端消えてなかったりはみ出してたりする。
クリッピング周りに不具合ありそう。
表題とは関係ないけど、こういうのも。
数十個のプリセットを公開したいと考えている。
投稿者 Takenori : 01:54 | トラックバック
2012年12月20日
α付き画像にα付き画像を重ねた時の誤差
パーティクルで、不透明画像にパーティクルを重ねていくものと、α付き画像に重ねていくものを作っているが、α付き画像どうしのブレンドは複雑で割り算が入り誤差が発生しやすい。
合成方法は不透明度付きピクセルのブレンドモード付き合成方法 に書かれている。
こんな感じ。
|
Ca = Fa+(1-Fa)*Ba |
単純な合成ならリンクの通りだいぶ省略できるけど、加算合成の場合は複雑。
吉里吉里2だと、α付き画像とα付き画像の通常アルファ合成だけがある模様。
後、MMX版は見当たらず、C版のみのよう。
C版は割り算等の部分をあらかじめ計算してテーブルに持っている。
通常合成のC版はこれでいいとして、加算合成の方は他のアルファ部分の乗数をテーブルで持って、除算が必要。
テーブル部分にあらかじめ除算値を入れていてもいいが、そうしたら誤差の影響かうまくいかなかった。
除算は、0~255 で割るのを加算、乗算、シフト にしてテーブルで持った。
SIMDで整数除算 に書かれている方法。
以下のメソッドで rcp, shift, bias のテーブルを作る。
divが割る値。
|
void short_rcp( unsigned short div, unsigned short& rcp, unsigned char& shift, unsigned char& bias ) { |
求めた値は、以下の式で使う。
x = (((x + bias)*rcp)>>shift)&0xff;
C版の加算合成は上記の方法で求められ、不透明画像に重ねていく方法と比較して違いがわからない程度になった。
α付き画像への通常アルファ合成と加算合成のC版は出来て、α付きのまま出力できるようになった。
次の問題はSSE2版。
テーブルが使えないので何とか精度を上げて変なところを解消したい。
変なところとは何個も重ねていると一部黒くなって線が見えてしまうところ。
精度を上げるため 255で割る処理は、>>8 で代用していたのを a = (a * 0x8081) >> (7+16) といった処理にするのと、128を加算して、四捨五入した。
割り算部分は、SSE を使い浮動小数点で逆数計算し、SSE2 でかける時は 128を加算し四捨五入。
ニュートン-ラフソン法 を使った逆数の精度向上は余り影響しないようなので止めた。
16bit固定少数での演算になるので、11bit精度のものを22bitに上げてもさほど影響しないのかもしれない。
SSE2版はこのように処理したら、一部黒くなって線が見えてしまうのは回避出来たが、加算合成時は四捨五入の128加算が多すぎるためかC版や不透明版の演算結果と比べて少し明るくなってしまう。
α付き画像にα付き画像を重ねる処理は重いので、あまり使わない方がいいが、状況によっては使いたい。
重ねる数が多いので、SSE2版が明るくなってしまうのはC版と比較すると目立つ。
何とかしたいところではあるが、SSE2版だけなら気にすることもないので、とりあえずはこのままで他の部分を作り込む。
投稿者 Takenori : 01:13 | トラックバック
pee 更新 演算誤差の件
更新。
pee ( Particle Effect Editor) β
演算誤差を解消したのと描画方法の指定を追加。
残りはソートとドキュメント、テストかな。
よくキャラクターの前とかに出るあれを作ってみた。
もうちょっとテクスチャを綺麗に作らないと綺麗にならないな。
このエフェクトには何か名前ついているんだろうか?
投稿者 Takenori : 03:44 | トラックバック
2012年12月21日
描画がカクカクする問題
更新。
pee ( Particle Effect Editor) β
pee で大きな絵をスクロールさせると顕著だったが、何かぷるぷるしているように見える問題がレンダリングして見てみると気になったので調べた。
原因は単純で小数点以下を切り捨てて描画していたから。
拡大コピーなど内部的には固定小数で処理しているので、描画矩形位置の指定も固定小数で渡すようにして描画するようにしたら綺麗に描かれるようになった。
内部的にはバイリニアとニアレストネイバーの両方を持っていたが、速度の都合上ニアレストネイバーで描画していたのを設定で指定可能にした。
これでどうも汚かったものが綺麗にレンダリング出来るようになった。
ただ、重いのでリアルタイムでは厳しい。
最適化しようと考えているが、重いのは重いままだと思う。
そもそもパーティクルはソフトウェア描画だと出しすぎると重いのはある程度仕方ないと思う。
可能な範囲内で最適化はするが。
後、エディタはハードウェア( DirectX )描画を指定できるようになっていたほうがいいか。
エディット中は速い方がいいだろうし。
レンダリングはソフトウェアでいいと思っているが。
バイリニアやスムーズなスクロールは、この雲を綺麗にするために改善した。
当然、他のものも綺麗になっている。
投稿者 Takenori : 04:47 | トラックバック
2012年12月29日
吉里吉里2本体のC++Builderでのビルド
吉里吉里2本体のオフィシャルビルドは C++Builder 5で行われていて、たぶん Deeさんくらいしか持っていないんじゃないかと思うけど、C++Builder 6でもビルドできて、2006、2007 でもビルド通るようになっているので、ビルドはこの4つバージョンのどれかでできる。
C++Builder 6 は不具合が多くてイライラするので、安定している 2007 の方が快適。
C++Builder 2009 から文字列周りの変更によって、吉里吉里2本体をビルドするにはまたいろいろと手を入れないといけないようになったらしい ( C++Builder 2009 でのビルドは試みていないので伝聞情報 )。
2006 は公開が停止され、C++Builder 2007 も購入できなくなってきていたけど、C++Builder XE3 を買うと、旧バージョン ( C++Builder XE2, XE, 2010, 2009, 2007 および C++Builder 6 ) はダウンロード可能になるようだ。
C++Builder XE3 製品ラインナップ の旧バージョンへのアクセス参照。
調べてみると、XE2 も同じように旧バージョンダウンロードできて、XE も一定期間ダウンロード可能だった様子。
これで C++Builder 2007 の入手性の問題はしばらく改善された ( されていた ) ので、本体ビルドがやりやすくなった。
投稿者 Takenori : 23:53 | トラックバック
2013年02月09日
TJS2をVC2012でビルドしてみる
TJS2 を VC2012 でビルドしてみた。
正規表現クラスは省き、出力出来るように Debug.message を加えただけのもの。
AO bench in TJS2 からウィンドウや描画部分を省いて実行すると、公式バイナリより10%程度速い。
ただ、吉里吉里2部分がないことによってメモリ消費量が少なくなっていたりするので、吉里吉里2全体をVC でビルドできるようにした場合も、この程度速くなるのかどうかは不明。
とは言うものの、コンパイラの変更で10%程度も速くなるのは魅力的ではある。
まあ、VC でビルドできるようにするにはかなり大変なんだけれども。
投稿者 Takenori : 13:26 | トラックバック
2013年02月26日
TJS2 バイトコードのバックポート
羽々斬 ( 吉里吉里Java ) で実装した TJS2 バイトコードの読み書きを吉里吉里2にバックポートした。
動作確認はしたが、詳細なテストはこれから。
テスト完了後公式リポジトリにコミット予定。
バイトコード対応によって得られる恩恵の一つは高速化だけど、これは11倍超くらいになった。
KAG3 のスクリプト読込みが自身の環境では 100ms 以上速くなり、起動速度の向上が体感できるくらい。
もう一つは難読化。
スクリプトからバイナリの塊になるので読めない。
作った自分でも読めないというか、読みたくない。
デバッグ時にバイナリやダンプを見てどこがおかしいのか調べているだけで発狂しそうになる。
バイトコードファイルフォーマットは羽々斬と同じだけど、細かい部分のIF仕様は少し異なっている。
execStorage で tjb ファイルへの読み替えはなくしている。
compileStorage でデバッグ情報の出力有無を切り換えられるようになっている(羽々斬では常にOFF)。
デバッグ情報は、バイトコードとスクリプト行情報の対応情報。
これがあると、バイトコードのどこかで例外が発生した時、スクリプトのどの行かわかる。
デフォルトでは出力しない。
デバッグ情報出しても、スクリプトのテキスト自体は含まれないので、対応するスクリプトは出ない。
"Bytecode." と言う文字列が出るだけ。
この辺りは例外発生時のダンプや dump メソッドコールすればわかる。
compileStorage の引数は以下の形。
Scripts.compileStorage( scriptfilename, outputfilename, isresultrequest, outputdebuginfo );
Java から C++ へは楽かと思ったが、言語仕様の違いからくる仕様の違いでミスりまくって不具合が出た。
リファレンスカウント方式かどうかとかバイトコード中の TJS2 レジスタアドレスがインデックスかアドレスか、バイトコードのインデックスかアドレスかなど順調にはまった。
開発は使いやすい VC で行ったから、TJS2 コマンドラインコンパイラが副産物として出来た。
こっちはメンテする気がないから有用性は微妙。
羽々斬との仕様の違い部分は、その内羽々斬側を合わせていきたいところ。
投稿者 Takenori : 19:36 | トラックバック
2013年02月27日
TJS2バイトコード対応コミット
TJS2 バイトコード読み書き機能対応をコミットした。
次回リリースされるバイナリから同機能が使用可能になるはず。
上記バイナリに含んでいるコンパイル補助スクリプトもコミットしている。
後、TJS2シンタックステストスクリプトもコミットした。
TJS2 のシンタックス周りのテストが必要な修正を入れた時役立つはず。
副産物のTJS2コマンドラインコンパイラも置いておく。
ソースコード付き。
メンテしないと思うので、修正が入ったら用済みに。
そもそもこれでコンパイルする必要があるのかどうか……
TJS2 を VC でコンパイルするたたき台にすると言う用途はある。
正規表現クラスは対応していないけど。
単純にバイトコードに置き換えて高速化/難読化するのであれば、コンパイル補助スクリプトを使って、スクリプトD&Dして、出来たバイナリにスクリプトを置き換えれば済む。
ちょっと高度なことをしたい人向けに説明書いておく。
コンパイルは以下のメソッドで出来る。
Scripts.compileStorage( scriptfilename, outputfilename, isresultrequest, outputdebuginfo, isexpression );
scriptfilename : TJS2スクリプトのファイルパス
outputfilename : 出力されるバイトコードファイルのパス
isresultrequest : 返り値を必要とするスクリプトかどうかを true / false で指定。デフォルト false
outputdebuginfo : デバッグ情報を含めるかどうかを true / false で指定。デフォルト false
isexpression : expression (式) かどうかを true / false で指定。eval する場合は必要。デフォルト false
最初の2つの引数は説明の必要がないだろうけど、後の3つは必要だろうと言うことで書く。
まずデバッグ情報は true にしても、私以外には意味がないと考えた方が良い。
デバッグ情報には バイトコードのインデックスとスクリプトの文字位置の対応情報が含まれ、例外が発生した場合などにその位置を特定するのに使われるが、スクリプトがないと何文字目付近かしかわからず、意味がない。
また、現状スクリプトとバイトコードを突き合わせて位置を示す機能などないので、このデバッグ情報があっても役立たない。
エラーや例外が発生したのなら、スクリプトで実行してその位置を特定して原因を究明することになるので、必要ないことになる。
もし、バイトコード読み書き機能が原因でエラーが発生しているのなら、デバッグに役立つがそのデバッグは私がやる可能性が高い。
返り値を必要とするかどうかは、Scripts.execStorage / Scripts.evalStorage で返り値が必要かどうかによって指定する。
evalStorage であれば、true に設定する可能性が高い。
通常は、false で問題ない。
式かどうかは、Scripts.evalStorage で呼び出すかどうかに依存する。
厳密には、Scripts.evalStorage で呼び出すかどうかは関係ないのだけど、式を eval する時に true にすると考えて問題ない。
後の3つの説明は以上。
何を言っているのかわからないのなら、全部 false か未指定でかまわないと言うか、補助スクリプトでコンパイルしておけばいい。
バイトコードの実行は Scripts.execStorage / Scripts.execStorage でスクリプトファイルを指定した時、そのファイルのヘッダーを見てバイトコードのものであればバイトコードとして扱われる。
TJS2 バイトコードファイルフォーマット は以前書いたものと同じ。
投稿者 Takenori : 23:02 | トラックバック
2013年02月28日
TJS2バイトコードの注意点
TJS2バイトコードはTJS2プリプロセッサ処理された後出力されるので、プリプロセッサで無効化されたりした部分は出力されない。
Cコンパイラなどと同じ。
TJS2プリプロセッサを積極的に使っている場合は注意が必要。
TJS2デバッガでの動作は不定。
そもそもバイトコード読んでTJS2スクリプトデバッガで動かそうとする人はあまりいないと思うが、動かすことを考慮していないので、現在のところ動作は不定となっている。
投稿者 Takenori : 03:48 | トラックバック
2013年03月04日
Array/Dictionary のバイナリ読み書き対応
Array/Dictionary のバイナリ読み書き対応したものをここに置いておく。
動作確認はしているが、詳細なテストはまだ。
Array/Dictionary の saveStruct の第2引数に "b" を入れると、バイナリ形式で書き出される。
後は、書き出されたファイルを eval でもして読み込めば使える。
KAG3 の保存モードで、"b" を指定すればそのままバイナリ形式対応になる。
読込みもそのまま可能なので、c や z 以外に b が追加されただけのように扱える。
それ以外に Dictionary のコンストラクタに引数を一つ追加可能になっていて、Dictionary に格納予定の個数を指定することでハッシュのサイズをあらかじめ大きくしておけるような変更が入っている。
ただし、即座に追加しないと次の RebuildHash で縮まるのでとりあえず大きくしておくようなことには使えない。
assign / assignStruct でも追加予定サイズでハッシュのサイズを大きくしておく修正も入っている。
これによって大量にデータが追加される時速度向上が期待されるが、数が少ない場合 RebuildHash が走ることで速度低下が起こりうる。
ラベルが大量 ( 数万 ) にあってセーブデータの読込みが遅い場合、劇的に高速化されるが、少ない場合効果は薄い。
データ読込みの高速化により起動速度は少し向上しているが、目に見えて早くなっているかというと誤差とも言える範囲。
Dictionary の引き数追加は、元々引数を書いていたら例外が発生していたので、互換性の面では問題ないが、仕様の変更が好ましいかどうかは難しいところ。
また、データが少ない時は大して速度向上の効果が得られないので、この機能追加は微妙。
テスト工数を考えると自分としては要らないかなと思うところなんだけど、必要な人はいるかな?
投稿者 Takenori : 23:46 | トラックバック
2013年03月06日
Array/Dictionary のバイナリ形式フォーマット
ほぼ MessagePack と同じようなものだけど、違う部分もあるので書いておく。
バイナリのシリアライズ可能形式である MessagePack を元に TJS2 で使用されるデータ等を考慮して少し変更したデータフォーマットを用いている。
バイトコードと合わせるために値はリトルエンディアン。
基本的には、型情報、長さ、値と続く。
型情報は1バイトで格納し、その型情報に従い長さ情報が付与される。
型自体が長さを表していたり、型情報自体が値を表しているものもある。
たとえば、小さい数値はそのままの値で格納され、int8 や int16 などは型自体が長さを表し、長さ情報を省略している。
辞書配列は、必ず文字列と値のペアで格納される。
最初にいずれかの文字列型がきて、次に他の型が入る。
配列や辞書配列を入れ子にすることも可能。
文字列は、TJS2 の内部型と同じ UTF-16 のまま入る。
| タイプ | 値 | 説明 |
| 正の整数固定値 | 0x00 - 0x7F | 正の整数の値 ( 0 - 127 ) はそのまま格納する。 |
| 負の整数固定値 | 0xE0 - 0xFF | 負の整数の値 ( -32 - -1 ) はそのまま格納する。 |
| NULL | 0xC0 | NULL値 |
| void | 0xC1 | void値 |
| true | 0xC2 | true値。TJS2では未使用。 |
| false | 0xC3 | false値。TJS2では未使用。 |
| String 8 | 0xC4 | 文字列型、長さ情報は1バイトで、1文字は2バイト。 |
| String 16 | 0xC5 | 文字列型、長さ情報は2バイトで、1文字は2バイト。 |
| String 32 | 0xC6 | 文字列型、長さ情報は4バイトで、1文字は2バイト。 |
| float | 0xCA | float値。値は4バイト。TJS2では未使用。 |
| double | 0xCB | double値。値は8バイト。TJS2では未使用。 |
| unsigned int 8 | 0xCC | 符号なし整数値、1バイト長の値。 |
| unsigned int 16 | 0xCD | 符号なし整数値、2バイト長の値。 |
| unsigned int 32 | 0xCE | 符号なし整数値、4バイト長の値。 |
| unsigned int 64 | 0xCF | 符号なし整数値、8バイト長の値。 |
| int 8 | 0xD0 | 符号付き整数値、1バイト長の値。 |
| int 16 | 0xD1 | 符号付き整数値、2バイト長の値。 |
| int 32 | 0xD2 | 符号付き整数値、4バイト長の値。 |
| int 64 | 0xD3 | 符号付き整数値、8バイト長の値。 |
| 固定サイズバイナリ列 | 0xD4 - 0xD9 | 0xD4(0個)~0xD9(5個)としたバイト列。型自体が長さを表す。 |
| バイナリ列 16 | 0xDA | 2バイト長でサイズを表すバイナリ列。 |
| バイナリ列 32 | 0xDB | 4バイト長でサイズを表すバイナリ列。 |
| 配列 16 | 0xDC | 2バイト長で個数を表す配列。 |
| 配列 32 | 0xDD | 4バイト長で個数を表す配列。 |
| 辞書配列 16 | 0xDE | 2バイト長で個数を表す辞書配列。 |
| 辞書配列 32 | 0xDF | 4バイト長で個数を表す辞書配列。 |
| 固定長文字列 | 0xA0 - 0xBF | 0xA0(0)~0xBF(31)の長さを持つ文字列。型自体が長さを表す。後に文字列が付く。 |
| 固定長配列 | 0x90 - 0x9F | 0x90(0)~0x9F(15)の長さを持つ配列。型自体が長さを表す。後に配列が続く。 |
| 固定長辞書配列 | 0x80 - 0x8F | 0x80(0)~0x8F(15)の長さを持つ辞書配列。型自体が長さを表す。後に辞書配列が続く。 |
ファイルを識別するためのヘッダーが最初に8バイト付与されている。
内容は以下の通り。
| 'K' | 'B' | 'A' | 'D' |
| '1' | '0' | '0' | \0' |
投稿者 Takenori : 03:00 | トラックバック
2013年03月29日
Array/Dictionary バイナリ読み書き対応コミット
Array/Dictionary バイナリ読み書き対応をコミットした。
Array/Dictionary のバイナリ読み書き対応 に必要な人いる?的な事書いたけど、それはぜひ欲しいと言う声はなかったものの、テストしてコミットしました。
変更点は、上のエントリーの内容と TJS2 バイトコード対応の公開関数 TVPExecuteBytecode の追加。
プラグインから TJS2 バイトコード読込み・実行用。
使う人ほとんどいないような気もするけど。
今回の修正で KAG3 の保存モードを"b"にすることで、異様に時間がかかるロードは劇的に高速化される。
後、スクリプトで Dictionary に大量のデータ追加したいとき、コンストラクタに想定している数を渡すことで、ハッシュサイズが最初から大きくなるので、追加が速くなる。
投稿者 Takenori : 22:32 | トラックバック
2013年04月01日
クラウドファンディングへ応募してみる
吉里吉里2 VC ビルド対応をクラウドファンディングのCAMPFIREへ応募してみた。
7営業日以内を目安に可否判定されるらしい。
4/10 までに掲載可能になるか否かがわかる感じか。
「C++ Builder でのみビルド出来る吉里吉里2 を Visual C++ でもビルド可能にし、吉里吉里2と同一ライセンスでオープンソースとしてソースコードを公開する」と言うものなんだけど、リターンがソースコードを公開すると言う辺りが少し微妙かな。
パトロンだけに何かリターンがあるわけじゃないので、その辺り懸念点ではある。
掲載された後も金額が集まるのかどうか気がかりだけど、それ以前に掲載されるかどうかの時点で厳しい気もしている。
何にしてもやってみないことには始まらないので応募した。
どうなることかな。
投稿者 Takenori : 23:59 | トラックバック
2013年04月03日
CAMPFIRE には掲載されず
クラウドファンディングへ応募してみる で書いたようにCAMPFIREへ応募したものは掲載見送りの連絡があった。
途中質問メールがあったのでもしかしたらいけるのかな?とも思ったけどダメだった。
特に理由等書かれていなかったので、今後の参考のためにも差し支えなければ理由(問題点や懸念点)を教えてくださいと返事した。
何がダメなのかわからないと対応のしようがないし、今後全没なのかよく分からない基準でうまくいったりするのか判断できない。
CAMPFIREがダメだったということで、次にREADYFOR へ応募した。
ここもダメとなると本件では国内のクラウドファンディングは使えないと判断するしかないかな。
投稿者 Takenori : 16:01 | トラックバック
2013年04月08日
吉里吉里2 VCビルド対応検討項目
C++ Builder でのみビルド出来る吉里吉里2 を Visual C++ でもビルド可能にする。
また、レガシー機能は削除して、モダンな機能取り込みも考慮する。
吉里吉里2 は C++ Builder 5 ~ 2007 でビルド可能ではあるが、この制限が保守性において懸念材料となっている。
オフィシャルビルドは C++ Builder 5 で行われているが、現在 C++ Builder 5 は入手できない。
この問題を解消するべく Visual C++ でもビルド可能にする。
保守性等のため完全互換ではなく、いくつかの機能の削除と VCL からの変更による挙動の変更が考えられるが、ゲーム実行等実使用において問題がない動作を目指す。
検討している内容を適用すると KAG3 はそのままでは動かない変更が入る。
Windows8 で顕在化してきている問題として以下の物がある。
・IME切り替え周りで VCL が使用している旧APIで問題があり、バイナリ書換えにより対処している。
・DirectX 7 の問題か、クリッピングがおかしくゴミが残る(C++BuilderでもDirectX 9等への対応は可能と思われる)。
これ以外にもいろいろと苦しくなってきている部分はある。
以下、変更検討事項。
問題等が予想される場合は、コメント等でご指摘いただければ再考する。
また、開発中に顕在化した問題によって他に変更が入る可能性もある。
予定している変更項目。
・VCL を排除。
・コンソールやコントローラー等のデバッグ機能の切り離し。
・DirectX 7 の描画は DirectX 9 へ変更。
・MIDI / CDDA / Pad クラスは削除。
・KAGParserクラスの本体からの削除。
・libjpg をSIMD版へ変更し高速化。
・zlib/libpng を最新版へ。
・エンジン設定用のオプションファイルはexeから分離、もしくはリソースへの移動。
・正規表現エンジンを鬼車へ変更。
・ERIフォーマットの非サポート。
・コンパイル時のワーニングを全てなくす。
・メニュー機能(Menuクラス)の削除デバッグオプションもしくはプラグインへ。
・その他 Windows/Layer クラスでいくつかのメソッドの削除。
・VCL を排除。
C++ Builder 以外でコンパイル出来るように VCL は排除する。
・コンソールやコントローラー等のデバッグ機能の切り離し。
コンソール機能はデバッガ側頼りにする。
ログファイルは残す。
コンソールやコントローラーのデバッグ機能はリリース時はない方が好ましい。
・DirectX 7 の描画は DirectX 9 へ変更。
Windows8 でクリッピング問題が出ているようなので、DirectX 9 へ変更する。
解決するかどうかは不明。
・MIDI / CDDA / Pad クラスは削除。
レガシーな機能と思われる。
・KAGParser は本体から分離。
現在はクラスプラグインが実現できるようになっているので、プラグインとした方が良い。
メンテナンスがきわめて困難なソースコードとなっているので、個人的には完全互換ではない別物にした方が良いと思っている。
・libjpg をSIMD版へ変更し高速化。
・zlib/libpng を最新版へ。
現状に合わせて置き換え
・エンジン設定用のオプションファイルはexeから分離、もしくはリソースへの移動。
ややトリッキーな方法なので削除。
・正規表現エンジンを鬼車へ変更。
boost の特定バージョンに依存した正規表現エンジンになっているが、移植性を上げるため鬼車へ変更する。
・ERIフォーマットの非サポート。
要らないと思われる。
・コンパイル時のワーニングを全てなくす。
エラーを探すのが辛いので、ワーニングは全てなくす。
・メニュー機能(Menuクラス)の削除デバッグオプションもしくはプラグインへ。
Windows 8 タブレットでフルスクリーン時にタッチだとメニュー出せないため、あっても使えない。
他の操作で出来るように組み込むべき。
ツール用途ではないと厳しいという意見を踏まえ、標準ではOFF 、デバッグオプションもしくはプラグインで ON 可能と言う形へ。
・その他 Windows/Layer クラスでいくつかのメソッドの削除。
Windows クラスのタブレット化において、問題となりそうな機能やゲームとして不要と思われる機能の削除。
ただ、互換性も考慮して取捨選択する。
Layer クラスで互換性のために置いているとドキュメントに記載されているメソッドの削除。
変更によって影響が出る可能性がある項目
VCL では、不可視のメインウィンドウを内部で作り、メッセージ等の処理をそこである程度行う様な構造になっているが、VC で作る場合、最初に生成されたウィンドウをメインウィンドウとして扱う一般的な方法にすると思われるので、細かい部分での挙動が変わる可能性がある。
krflash は非サポートとなる可能性がある。
工数の関係から状況次第で対応検討項目。
・マルチタッチ対応。
・フリック等ジェスチャー系の入力。
・ペン入力。
・画面の向き対応。
・Ogg Vorbis を高速化プロジェクトのものへ置き換え。
・アセンブリコードをイントリンシックで書き換え、SSE2 のサポート。
・64bit対応(イントリンシック書き換え必須、ポインタサイズ考慮必要)。
投稿者 Takenori : 20:35 | コメント (4) | トラックバック
吉里吉里2 VCビルド対応ファンディング調査
吉里吉里2 VCビルド対応検討項目 を実現するためにお金集めようと言うエントリー。
見積金額 200万円。
上述のエントリー内容を実装し、動作確認が出来た段階で吉里吉里2と同じライセンスで公開。
みんなで叩いてバグを減らす。
工数の関係から状況次第で対応検討項目は集まった金額次第で考慮。
1万円単位で○万円出してもいいと言う人がいれば、メールを下さい。
人数分契約書を作って、開発するという方式を考えています。
1万円単位と書いたのは、事務手続きの関係からです。
何千枚も契約書作るのは現実的ではないので。
契約書を作る関係で、住所と名前が必要なのでそれを私に明かしても良いという人限定です。
また、ドキュメント等のコントリビューター項に載せる名前は別の方が良い方は、その名前。
コントリビューター項に載せないで欲しい場合は、その旨記載してください。
メールには以下の内容を書いてください。
・住所と名前
・金額
・コントリビューター項に載せる名前
・支払い時期
・契約書ひな型で問題ないか否か
・紙の契約書が必要かどうか
一応自分は1人月分くらいは負担する心づもり。
他に1人月分くらいは出す、20万出すという話あり。
以下、宣言してくれた人のつぶやき貼り付け。
twitter で jin1016 宛 へ宣言リプライもらえたら追加します。
@jin1016 20万ぐらいなら出す
— でぃー子bot@動く猫しっぽアクセ制作中さん (@wdko) 2013年4月8日吉里吉里VC対応、そんなに出せないけど5万なら大丈夫。(`・ω・´)
— casperさん (@m_casper) 2013年4月8日@jin1016 じゃあ、ちょっと後で社内で検討するけど、予告10万くらいで。主にWin8ユーザとしての期待でw
— まかべひろしさん (@sinpen) 2013年4月8日これは出さざるを得ないがお金ないー。3万くらいならなんとか。メニューは不便だけどまあ何とかなるだろう
— 小松直矢(sakano)さん (@kasekey) 2013年4月8日@jin1016 吉里吉里2 VCビルドの件、個人的に5万と可能な範囲でVCLの代替コードを提供します。会社としても社内で検討してみます。
— 青猫さん (@AonekoSS) 2013年4月8日@jin1016 要は寄付だよね?10万ならだすよー
— tomoyuki nagaiさん (@nagai7) 2013年4月8日@jin1016 財政状況確認してからになりますが、5万円は出せるかなと思います。
— ルー@修羅場中さん (@Ruw) 2013年4月8日@jin1016 では3万円の予定で…
— 掃除しなきゃbot ズレメガネさん (@giw) 2013年4月8日@jin1016 メニューありということならまず個人で5万出します。
— ゆんゆん探偵はくんくん探偵リスペクトさん (@yunyundetective) 2013年4月8日@jin1016 了解しました、取りあえず3万予定でお願いします。 支払期日や何回かに分けるのありならもう少しいけるかもしれません
— 永劫さん (@eigoh_pg) 2013年4月8日吉里吉里2VCビルド対応プロジェクト? ふむ。 まぁ、じんさんだし私からは5万ぐらい出しますか……
— りょうごさん (@Ryogo_PL) 2013年4月8日@jin1016 分納とか、後払いとか、そんなんでもよろしければ3万ほど。
— うめ/AZ-UMEさん (@_AZ_UME_) 2013年4月8日@jin1016 開発契約なのですね、失礼しました。四月から月1で1口で九月分までの分納でオナシャス/(^o^)\
— 京 秋人さん (@aki_kar) 2013年4月8日@jin1016 ワムソフトからは+50でよろ
— わたなべごうさん (@wtnbgo) 2013年4月9日@jin1016 最低額で申し訳ないですが1万円出します
— ぢゃくそんさん (@_jackson) 2013年4月9日@jin1016 では遅ればせながら2万出させていていただきます!小額ですみません(^ω^;
— アザナシさん (@azanashi) 2013年4月9日@jin1016 ありがとうございます とりあえず2万円ほどの額になるかと思いますがご支援させていただこうかと思います
— 靄間 一郎さん (@i_moyama) 2013年4月9日投稿者 Takenori : 20:40 | トラックバック
2013年04月09日
メニューについて補足
ウィンドウの標準的なメニューはレガシー な機能か?と言と、現時点ではそうでないとしても片足突っ込んでいる状態と思う。
なくす、なくさないを考えると、その境界線上にある機能。
今はまだ互換性のためにあった方が助かる機能だけど、将来的には削ってしまいたいものだろう。
フルスクリーンの場合にタッチで操作できないと言うのは、現状ある直接的な問題だが、タブレットやスマートフォンへの移行を考えると代替手段の準備はほぼ必須になるのは間違いない。
また、移植性を考慮したデザインへの移行を促したいとも思う。
反対意見が出るのは承知で書いた。
それでも時計の針を進めたかったと言うこと。
まあ、メニューがあるのならお金出すと言う人がいるのなら、じゃあ標準ではOFF 、デバッグオプションもしくはプラグインで ON 可能と言う形にすると言う話でもあるけども。
プラグインで実現可能なら、その形が濃厚かな。
投稿者 Takenori : 01:35 | トラックバック
吉里吉里2 VCビルド対応 諸条件
吉里吉里2 VCビルド対応ファンディング調査で記載しておらず、聞かれたことなどを書きます。
VC は、最新版である Visual Studio 2012 (C++) Pro で対応する。
OS は VS2012 の制約により、XP 以上となる。
スケジュール は以下の通り。
最終期限は、今年いっぱい(2013年12月末)まで (契約書上の期限)。
予定スケジュール
実装期間 : 4月~6月
テスト期間 : 7月、8月
支払いは前払いが好ましいが、後払いでも可。
後払いの場合、完了月の翌月末まで。
予定通り進めば9月末まで。
テストは規模的に一人で全て網羅は無理なので、実装完了後公開しみんなに叩いてもらうことを想定しています。
もちろんテストは順次進めますが、安定性向上のためには多くの方の協力が必要になります。
名前と住所についてですが、公開されるのは私個人のみにです。
公に公開されるのは、「コントリビューター項に載せる名前」でなしでも問題ありません。
契約書
後ほどひな型を公開します。
形式的に受託開発となります(寄付(贈与)ではありません)。
内容が関連する方は確定申告にて経費として申告可能と思われます。
投稿者 Takenori : 16:11 | トラックバック
吉里吉里2 VCビルド対応ファンディング途中経過
一晩経った現在の状況です。
| 提供者 | 金額(万円) |
| deeさん | 20 |
| casperさん | 5 |
| (有)MCFさん | 10 |
| sakanoさん | 3 |
| 青猫さん | 5 |
| nagaiさん | 10 |
| Ruwさん | 5 |
| giwさん | 3 |
| ゆんさん | 5 |
| 永劫さん | 3 |
| りょうごさん | 5 |
| AZ-UMEさん | 3 |
| 京 秋人さん | 6 |
| Katsumasa Tsuneyoshiさん(メールにて) | 3 |
| ぢゃくそんさん | 1 |
| miahmieさん(コメント欄にて) | 5 |
| サークル獏さん(メールにて) | 3 |
| アザナシさん | 2 |
| はっしぃさん(メールにて) | 5 |
| 靄間 一郎さん | 2 |
| わっふるさん(メールにて) | 2 |
| M2さん | 50 |
| ワムソフトさん | 50 |
| ノーツさん(メールにて) | 50 |
| 自分 | 50 |
| 合計 | 306 |
投稿者 Takenori : 16:14 | トラックバック
吉里吉里2 VCビルド対応契約書ひな型
支払い条件については、前払い、分割払い、後払い等要求条件によって、変更可能です。
出来れば前払い(4月末日)にしていただけると助かります。
支払い月は後払い期限(9月末日)までの間で変更可能です。
その他修正した方が良い項目がある場合は、個別、もしくはコメントでお願いします。
この契約書ひな型はたたき台です。
特に問題ない場合は、このまま印刷して送付します。
2013/04/10
第5条に「修正BSDライセンス」に関係する記述を追加
ただし、乙は、その成果物を最終的に「吉里吉里ライセンス」および「GPL」のデュアルライセンス、もしくはW.Dee氏指定のライセンスを加えたトラプルライセンスで、甲および「吉里吉里プロジェクト」及びそれを利用する第三者に対して提供するものとします。
W.Dee氏指定のライセンスが修正BSDライセンスの場合、修正BSDライセンスで甲および「吉里吉里プロジェクト」及びそれを利用する第三者に対して提供するものとします。
2013/04/11
最後の方で
修正前「本契約の成立を証するため、本覚書二通を作成し、」
修正後「本契約の成立を証するため、本契約書二通を作成し、」
他に
修正前「トラプルライセンス」
修正後「トリプルライセンス」
の2点を修正。
------
ソフトウェア開発業務委託契約書
貴方の名前(以下「甲」という)と私の名前(以下「乙」という)は、次の通り業務の委託をするにあたり、次の通り合意し、契約(以下「本契約」という)を締結する。
第1条(本件ソフトウェア)
本件により乙が開発するソフトウェアは以下のとおりとする。
「吉里吉里2 VCビルド対応」
第2条(業務の範囲)
本件業務の内容は、以下の通りとする。
1.業務概要
吉里吉里2 を Visual Studio 2012(C++) Professional でビルド可能にする
2.業務詳細
・吉里吉里2 を Visual Studio 2012(C++) Professional でビルド可能にする。
・MIDI / CDDA / Pad クラスは削除する。
・その他詳細仕様及び設計詳細は乙に一任する。
3.スケジュール及び納品
・作業スケジュール
自 2013年4月10日 至 2013年12月31日
・納品
吉里吉里2と同一ライセンスでソースコード及び実行バイナリコードを一般に公開し2カ月間のテスト期間経過後納品完了とする。
その後、W.Dee氏の了承のもと吉里吉里プロジェクトに対してコードを規定のライセンスで寄贈する。
納品は上記スケジュールより前倒しでも可能とする。
第3条(対価及び支払条件)
1. 甲は乙に対して本業務の対価として金\○○円也(消費税込)を以下の通りに支払う。
2. 甲は、本業務の対価を、4月末日までに乙の指定する銀行口座に振り込むことにより乙に支払う。
( 2. 甲は、本業務の対価を、納品完了後末締めで翌月末日までに乙の指定する銀行口座に振り込むことにより乙に支払う。)
第4条(瑕疵担保責任について)
本契約に基づき作成されたプログラム等に瑕疵があった場合、乙は、公開後2カ月間のテスト期間のみ修正を受け付け、その後の修正は任意の対応とする。
第5条(著作権並びに著作人格権について)
本契約に基づき乙が作成し提供するプログラム等の権利(著作権法第21条から第28条に定めるすべての権利を含みます)はそのまま乙に属するものとします。ただし、乙は、その成果物を最終的に「吉里吉里ライセンス」および「GPL」のデュアルライセンス、もしくはW.Dee氏指定のライセンスを加えたトラプルライセンスで、甲および「吉里吉里プロジェクト」及びそれを利用する第三者に対して提供するものとします。
W.Dee氏指定のライセンスが修正BSDライセンスの場合、修正BSDライセンスで甲および「吉里吉里プロジェクト」及びそれを利用する第三者に対して提供するものとします。
第6条(協議)
本契約締結後に記載内容に変更が生じた場合は、甲、乙協議の上、書面により別に定めるものとします。
本契約に定めのない事項又は本契約の内容等に疑義が生じた場合には、その都度、甲、乙双方が民法をはじめとする法令等を踏まえ、誠意をもって協議します。
本契約の成立を証するため、本覚書二通を作成し、甲乙記名捺印の上、各自一通を所持する
平成○○年○○月○○日
甲: 貴方の住所と名前
乙: 私の住所と名前
------
投稿者 Takenori : 20:32 | トラックバック
2013年04月11日
吉里吉里2VC対応追加項目希望アンケート
金額が見積もりより多くなっているので、追加で何が欲しいかコメントください。
以下に、検討項目に上げていたものなどを列挙するので、この中からこれが欲しいというのがあればそのコメントも下さい。
コメントはツイッターやメールでもかまいません。
検討していた項目の内、入れるのがほぼ確定しているもの
・マルチタッチ対応。
工数の関係から状況次第で対応検討項目。
・フリック等ジェスチャー系の入力補助。
・ペン入力。
・画面の向き対応。
・Ogg Vorbis を高速化プロジェクトのものへ置き換え。
・アセンブリコードをイントリンシックで書き換え、SSE2 のサポート(工数大)。
・64bit対応(イントリンシック書き換え必須、ポインタサイズ考慮必要)。
追加で上げられているものや思い付くもの
・Layer クラスから Image クラスを分離可能にする。
・KAG3 では対応しなくなるので、ポストKAGを作る。
・Layer.operateAffineで引数mode指定時の未実装機能。
・Octet の未実装メソッド追加
・KAGParser に近い機能を持ち再実装したもの。
・TJS2 のコンパイル部分の整理。
・マルチプラットフォーム化。
・Layer クラスから Image クラスを分離可能にする。
ツール作るときなどに色々と苦労するようなので。
・KAG3 では対応しなくなるので、ポストKAGを作る。
KAG3 に相当するものがないと困る人が多いと予想されるため。
・Layer.operateAffineで引数mode指定時の未実装機能。
あった方が便利。
・Octet の未実装メソッド追加
あった方が便利。
・KAGParser に近い機能を持ち再実装したもの。
現状のKAGParserのソースコードは保守性が低いので、だいたい同等機能のものを作った方が保守性が上がる。
・TJS2 のコンパイル部分の整理。
少し見通しが悪いので。
・マルチプラットフォーム化。
よくある要望。
現在の win32 フォルダ内のソースコードは厚いので、もっと薄いプラットフォーム互換維持層を作り、その API をコールすることで移植性を高める構造へ持っていく予定ですが、マルチプラットフォーム化までは工数的に無理と思われます。
-----
追加
・Layerクラスは画像処理系とイベント処理系を完全に分離して,TJSスクリプト側で互換を取る。
TJS2 に foreach を組み込む。
ScriptsExプラグインの Scripts.clone() を本体に組み込む。
オブジェクト内のメンバ存在チェックメソッド を本体に組み込む。
TJS2 で型指定も可能にする。
TJS2 に JIT を導入して高速化する。
TJS2 に型推測を入れて高速化する。
TJS2 にコルーチンが欲しい。
TJS2 にrubyのブロックみたいなのが欲しい。
TJS2 にパッケージ機構が欲しい。
シリアライズ機能が欲しい。
投稿者 Takenori : 17:32 | コメント (2) | トラックバック
2013年04月12日
吉里吉里2 VCビルド対応の流れ
吉里吉里2 VC ビルド対応を実現するため、クラウドファンディングサイトの CAMPFIRE に応募してみるも断られる。
続いて READYFOR にも応募してみるも断られる。
対応検討項目 を上げた後、独自でファンディングを行うべく ファンディング調査 を公開し、お金を出してくれる人を募る。
質問等を受けて 諸条件 を公開。
( メニューの扱いについて補足説明追加 )
ファンディング途中経過 を報告。
契約書ひな型 を公開。
メールをもらった方と順次契約等手続きを行う。
当初見積もりよりも多く集まったので 追加項目希望アンケート を実施中。
吉里吉里2 VC ビルド対応って結局何?
主目的は……
・保守性の改善による開発効率のアップとソフトウェア寿命の長期化。
・コンパイラ入手性改善による開発者増加と発展。
その他にマルチタッチ対応などによるタブレット端末最適化に向けた下回り整備も行います。
また、副次的効果として個別バイナリを作りやすくなることからクラッキング対策の強化が行いやすくなります。
投稿者 Takenori : 13:52 | トラックバック
2014年06月28日
えもふりをアルファチャンネル付き動画で
えもふり が公開されたので少し試してみた。
アルファ付きで連番PNG書き出しが出来るようなので、アルファチャンネル付き動画にしてしまえば、吉里吉里で自由に再生できる。
こんな感じ。
えもこだよ! えもふりは個人利用してもらう分には使い方に特に制限はしてないんだ。常識的な範囲でなら同人活動なんかに使ってもらっても全然オーケーだよ! えもふり E-mote Free Movie Maker ちぇきら! http://t.co/PVMDEM04e8 #E_mote
— えもこ先生 (@M2_emote) 2014, 6月 27常識的な範囲でなら同人活動OKと言うことなので、ある程度は使えるのかな。