2005年12月08日
必要環境
まず、どのような環境において再生可能にするかを考える。
可能であれば、組込み環境においても再生可能な方が望ましいので、あまりPCのOSに頼った機能は使いたくない。
と言っても、今までまともに使ったことのある組込み系OSは一つだけ。
しかも、マイナーなやつ。
ITRONとかだったら良かったのだけど。。。
ま、それはいいとして、少なくとも次の3つは欲しい。
・スレッド(タスク)
・排他処理機構(クリティカルセクションorセマフォorミューテックス)
・タイマー
これぐらいであればOSと呼ばれるものが詰まれている環境にはあるだろう。
後、使うかもしれないのは同期メカニズム ( Event ) かな?
とりあえず、コールバック関数的なものを用意しておけば、イベントへの依存はなくせるだろうけど。
イベントに限らず、ウェイト部分をコールバック関数のようなものにしておけば、様々な環境に対応しやすい。
投稿者 Takenori : 03:43 | トラックバック
エンディアン
マルチプラットホームと聞いて、だいぶ前からどうするかなぁと思っているのが、ビッグエンディアンへの対応。
最近はネットワークバイトオーダーにしているものが多いのだろうか?
liboggを見たところMac OSにも対応しているようなので、大丈夫かな。
ま、liboggは使わなさそうだから、その辺りを書く時は気を付けなければならないけど。
後は最終段の出力。
RGBかBGRかなど。
ビデオチップなどは共通だろうからそこも気にしなくて済むのかな?
ま、その辺りはポーティングする際に書き換えることがあっても仕方ないだろう。
投稿者 Takenori : 04:01 | トラックバック
2005年12月09日
Playerの構成
どのようなデザインにするか考え中。
DirectShowは面倒でややこしいが、かなりよく考えられた仕組みだ。
ピンとフィルタ、メディアサンプルが構成要素で、フィルタをピンでつないでメディアサンプルをアップストリームからダウンストリームへ送る。
基本的な仕組みはそんなところだ。
ただ、単に動画を再生するだけであれば汎用的過ぎる。
動画を再生するのに必要なものを大別すると次の4つになるだろうか。
・入力ストリーム
・デマルチプレクサ
・デコーダー
・レンダラ
入力ストリームは、入力ソースに柔軟性を持たせるために必要になる。
ファイル以外にも、メモリ上からやネットワーク越しなどソースが与えられる場所を選択できるようにするために不可欠だろう。
デマルチプレクサは、マルチプレクスされたデータを分離するのに必要。
Theoraなら、Oggをデマルチプレクスする必要があるし、他のコンテナ形式が使われる可能性もある。
コンテナ形式にあわせて作る必要があるだろう。
デコーダーは、符号化されたデータを復号化するのに必要になる。
復号化後に、色空間変換が必要になる可能性があるけど、これはレンダラでやった方が良いだろうか?
復号化途中に同時に色空間変換をやってしまった方が効率的になる可能性もある。
デコーダーもしくはレンダラでやるようにするかな。
特殊な出力形式などに対応する場合、レンダラでやった方が対応しやすいこともあるだろう。
レンダラは、最終出力装置にデータを送るのに必要になる。
様々なものに出力する可能性があるので、出力するものごとに作る必要があるだろう。
とりあえず、この4つが分離されていればそれなりに汎用的になるだろう。
悩んでいるのはDirectShowのピンのような仕組みを導入するかどうか。
そのような仕組みを導入するとかなり汎用的になる。
再生以外の用途にも使えるようになる。
が、あまり汎用的にしすぎると収拾がつかないので、ある程度のところで絞る必要がある。
ただし、DirectShowのピンやフィルタは概念的な意味合いも多い。
フィルタの機能の大部分がピンにあったり、ピンの機能がフィルタにあったりと、内部的にどちらにどのような機能があるかは作る人の裁量に任せられている。(そもそもピンやフィルタはインターフェイスなので実装はどうとでもなる)
どうするかなぁ。
投稿者 Takenori : 23:15 | コメント (2) | トラックバック
2005年12月10日
Theoraプレイヤー
解凍したらplayer.exeがあるので、コマンドラインでplayer ***.oggとすれば実行できる。
"***.ogg"は任意のTheora動画ファイル。
とりあえず、負荷がどんなものかなと思って息抜きに作ってみた。
Vorbisのデコードは行っておらず、プレゼンテーション時間を待つなどの処理もしていない。
全力でTheoraのデコードをし、デコードしているフレームの番号がひたすら表示するだけのプログラム。
yuvからRGBへの変換も行っていない。
ビルドオプションでSSEを使う設定にしたので、PenIII or Athlon XP以降でのみ動作する。(と思う)
見てみると、遅くなったり速くなったりする。
でも、絵がないのでどのようなシーンで遅くなるのか良くわからない。(たぶん、動きの激しいシーンだと思うが)
一応libtheoraに付いていたサンプルをベースにしたソースを付けているので、ある程度改良できるはず。
libtheoraのサンプルソースよりはだいぶ見やすくなっていると思う。
でも、絵がないとつまらないな。
絵ぐらい出せるようにしてみるかな。
あと、フレームごとにデコード時間などを取得し、ある程度解析できると助かるかも。
ここから最適化するにしても、それらのデータがないと速くなったのかどうかよくわからないし。
投稿者 Takenori : 01:16 | トラックバック
2005年12月11日
libtheora-mmx
昨日のプレーヤーは絵が出なくて楽しくなかったので、Overlayを使って絵が出るようにした。
mmxtheora.zip
※これを使用したことによって発生するいかなる問題に対しても私は責任を負いません。自己責任で使ってください。
使用上の注意
ビデオカードがオーバーレイとオーバーレイでのYV12をサポートしていないと再生できない。(例外投げっぱなしなので、いきなり落ちると思われます)
再生するファイルは、同一フォルダに置かれた"test.ogg"のみ。
昨日同様SSEオプション付きなので、PenIII or Athlon XP以降でのみ動作。
DirectXが必要。
デバイスをロストしてもリセットしないので、タスクマネージャは事前に出しておいたほうが良い。
後、ついでに表示する時間も待つようにしたので、ほぼキチンとした時間で描画されているはず。
ただし、timeGetTimeで時間を取得しているために1ms単位になっているせいか、プレゼンテーション時間をms単位でぶった切っているせいか、バッファリングしていないせいか、たまにカクカクする気がする。
libtheora-mmxは、VCでビルドできなかったので、インラインアセンブラで書かれているところはMinGWでコンパイルした。
MinGWでコンパイルしたのをVCのライブラリアンで固め、そのライブラリをリンクした。
大丈夫なのかなぁ? と思ったが、いけた。(っぽい)
で、実際の効果だが…… 気持ち軽くなった気がするようなしないような。
解凍して出来るovplayermmx.exeがlibtheora-mmxを使ったもので、ovplayer.exeは使っていない。
VBRで圧縮した時、クオリティを高く(80%程度)するとかなり重くなるようだ。
640*480*30fpsをAthlon XP 1600で再生したら、かなり動きの激しいシーンでドロップフレームが発生した。(P4 3GHzでは余裕)
60%程度にしたらギリギリ落ちていなさそうだった。
テストパターンがそれほど多くないのではっきりとは言えないが、どうも高速にスクロールする場面で負荷がかなり高くなるようだ。
RGBへの変換なし(YV12のまま)での出力&音のデコードを行っていない状態でこれとは……
現状のままだとしても、音が入ることを考えると2GHzぐらいは欲しいだろうか。
しかも、オーバーレイでのYV12サポートがあるとして。
激しいシーンがいきなり現れない&続かなければ、バッファリングすることによって何とかなるかもしれないけど。。。
さて、どうしたものか。
libtheora本体にも手を加えていかないとダメかなぁ。
投稿者 Takenori : 05:52 | コメント (3) | トラックバック
2005年12月12日
CRCチェック スルー
liboggの部分を書き起こすべくliboggのソースを読んでいると、読み込んだデータのCRCが合っているかどうかチェックしていた。
こんなものいらないと思って外してみたが・・・
そんなに負荷は下がらなかった。
CPU負荷ではわかりづらいので、この前のSamplePlayerを時間を吐くように書き換えて計測してみた。
何もしていないのを100%とすると・・・
85.7% libtheora-mmx使用
85.2% さらにCRCチェックをはずしたもの
82.6% さらにP4用に出来る限りの最適化オプションをつけたもの
CRCチェックをはずしても0.5%しか縮まらないとは。
liboggを書き換えても大して縮まらないかもしれないな。
所要時間をトータル時間で割ると19.6%だった。
ムービーは640*480 30fps VBR 90%で、環境は、P4 3GHz + DDR2-533。
ちなみにAthlon XP 1600の方では44.2%だった。
これだけ見ると何とかなりそうだけど、ピーク時の負荷を出すと厳しくなるんだろうな。
各フレームのデコード時間を出せば、ピーク時の負荷になるかな。
投稿者 Takenori : 09:29 | トラックバック
負荷分布
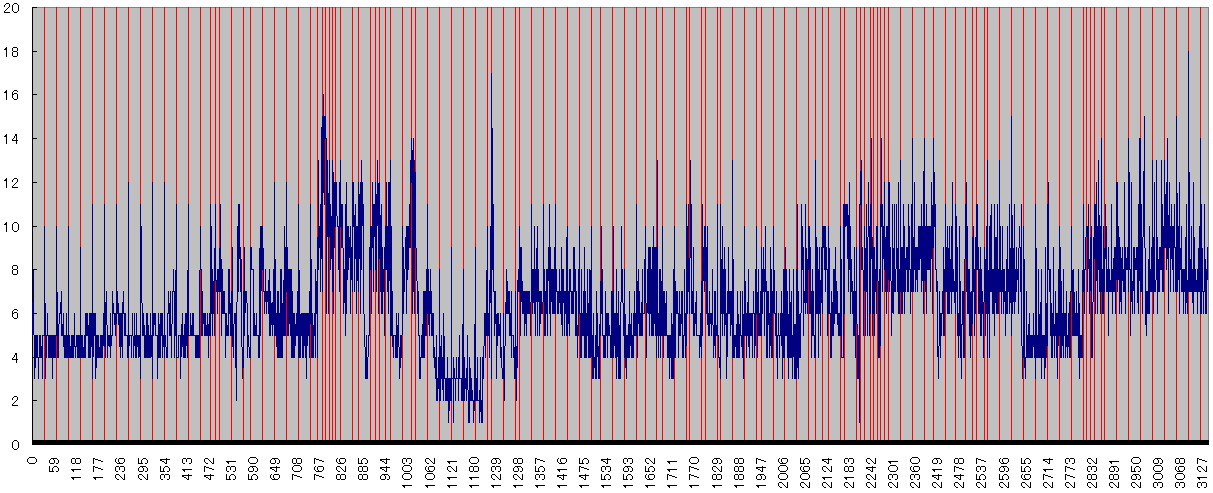
グラフは各フレームのデコード時間とキーフレームを重ねたもの。
青がデコード時間で、赤い線がキーフレーム。
時間がかかっているフレームは大体キーフレームと重なる。
シークをしない場合、キーフレームは必要ないので出来るだけ間隔を大きくとる設定にした方が容量削減と負荷低減につながりそうだ。
上のグラフはキーフレーム間隔を32フレームにしたものなので、同一ムービーのキーフレームの設定を65536フレームにしてエンコードしてみた。
結果は下図の通り。

ファイルサイズは3.2%小さくなり、処理時間は1.6%縮んだ。
グラフを見ると負荷が高くなる箇所が減っているが、傾向は大体同じ。
ま、キーフレームが減ったので負荷が高くなる箇所が減ったのは当然だろう。
再生してみた感じは大して変わらない。
シークを使わないゲームの場合はキーフレーム間隔は最大値にしておいた方が良いかも。
シークが必要なものでも、シーク位置が決まっているのであれば、そのフレームにのみ強制的にキーフレームを挿入すればいい。
この負荷分布の傾向からバッファリングするフレーム数の最適値がある程度求まるかも。
当然、テストケースをもっと増やさないといけないが。
後、デコーダーのバージョンが上がると傾向も変わるかもしれないので、その辺りはリリース時に調整だろうか。
投稿者 Takenori : 20:20 | トラックバック
2006年02月07日
ムービーコデック
久しぶりにtheoraを見てみたが、特に変わったところはないよう。
もうしばらく動きはないのだろうか。
YV12からRGB32への変換の最後で述べたようにMPEG Iはかなり軽くなりそうだ。
VLC media playerでMPEG Iのファイルを再生するとCPU負荷は極めて低い。
と言うことで、VLC media playerが使用しているMPEGデコーダーを見てみたのだが、どうもlibmpeg2が使われているようだ。そして、libmpeg2のライセンスはGPL。
ffmpegは、LGPLだけどいくつかのライブラリはGPLのものが使われているみたい。ざっと見た感じでは、MPEG 1デコーダーはLGPLのよう。
The MPEG Libraryは、独自ライセンスのよう。著作権表示と免責条項を貼り付けておけば使えるっぽい。BSDライセンス?
後は、MPEG.ORGが配布しているソースか。これについてはライセンスは見ていない。
The MPEG Libraryのライセンスはゆるいけど、ビデオデコーダーしかない。DemuxやAudioは別。
Demuxは仕様さえわかれば作るのはそんなに大変じゃないし、Audioは他から取ってくるという手もある。MP2とかだったら他にいろいろとありそうだし。
でも、The MPEG Libraryはデータの読み込みにファイルストリームを期待しているのがどうも。
うーむぅ。
投稿者 Takenori : 18:43 | トラックバック
2006年06月10日
Linuxでのビデオアクセラレーション
Linuxでは、XVideoによって、YUV形式などで直接書き込むことが出来るっぽい。
XFree86 DRIでもビデオアクセラレーションが使えるようだが、こちらは3D 系用みたい。
結局のところまだ良くわかっていない。
このPDFを見ると、オーバーレイで再生できるような気はする。
まあ、現状はこれで出来そうってだけでいいかな。
投稿者 Takenori : 17:46 | トラックバック
libtheora 1.0 alpha6
libtheora 1.0 alpha6
気付いたら 5/30にリリースされてた。
てか、まだα版で引っ張るのか。
主な更新点は、バグフィックスと theora-mmx のマージと書いてある。
中身はまだ見ていない。
投稿者 Takenori : 18:08 | トラックバック
SMPEG
前から適当なMPEGデコーダーがないかなぁと探していたわけだが、SMPEGと言うものを知った。
SDLでMPEG Iを再生するためのライブラリだとか。
標準でSDLに組み込まれているわけじゃなくて、別に配布されていてライセンスはLGPL。
ここからソースを取ってきて、おもむろにビルド。
負荷を見るとVLCなどと大体同じぐらいのようなので、今の吉里吉里2のMPEG I再生よりもかなり軽い。
理由は単純明快、YV12で直接オーバーレイレイヤーに描いているから。
吉里吉里2でVMR9をサポートしたので、OSについているMPEG IデコーダーもYV12で直接描けても良さそうなものだけど、なぜかRGB32に変換して描くので遅い。
まあ、それはともかくソースコードを見てみた。
当たり前のようにSDLに依存している。
後、何だが見覚えのあるようなコード・・・と思ったら、The MPEG Libraryだ。
どうやら、The MPEG Libraryを改造して作った様子。
まあ、1から作るのは辛いし、GPLじゃないのと言ったら限られてくるのだろう。
自分もThe MPEG Libraryぐらいしかないかなぁと考えていたし。
MPEG IデコーダーはSMPEGを改造して作るかな。
SDLに依存している部分と入出力部分はかなり手を入れることになると思うけど。
ライセンスはSMPEGのLGPLを引きずって、LGPLになるけど、デコーダーはDLLとして分離しやすいから大丈夫だろう。
投稿者 Takenori : 23:15 | トラックバック
大まかなデザイン
・入力ストリーム
・Demux+デコーダ
・レンダラ
基本はこの3つで構成することにしようと思う。
制御方法はDirectShow と同じようにする。
再生速度のタイミングはレンダラがとる。
Demux+デコーダは、スレッドを持って、ただひたすらデコード。
デコードされたデータを受け取ったレンダラがプレゼンテーション時間になるまでブロックする。
再生や停止はレンダラからDemux+デコーダへ伝える。(レンダラがブロッキングしているので、それを解除してからでないとおかしなことになりうる)
細かいシーケンスはもう少し詰める必要があるとして、大まかにはこんな感じでいいだろう。
でも、デコーダを差し替えられるようにするとレンダラとのネゴシエーションはいろいろと面倒だなぁ。
投稿者 Takenori : 23:45 | トラックバック
2006年06月13日
プレイヤーとWiki
今までは、ブログの下書きに考えたことをメモしたりしていたけど、下書きのようなものはWikiの方へ書くことにした。
ある程度まとまったり、思い付いたことなどは、今まで通りブログに書くことにする。
そして、時々Wikiで整理して、最終的にWikiできれいに整理されている状態にしたい。
うまくいくかどうかはわからないけど。
SMPEGを改造して、簡単なプレイヤーを作ることにした。
改造といっても、入力と出力部を変える予定なので、かなり最終形に近いものになるはず。
入力は、SDLのものから、独自のクラスへ。
出力も、同じように変更する予定。
SMPEGによってMPEG I再生が出来た後、ある程度設計してTheoraに取り掛かろう。
とりあえずビデオはDirectXのオーバーレイへ描くなりなんなりするとして、オーディオはどうしよう?
やっぱりOpenAL?
吉里吉里3のをとってきて鳴らす?
先にビデオから作るので、その後考えよう。
たぶん、OpenALにすると思うけど。
ってことで、まずは wxOverlayWindow (仮)とか作るかな。
投稿者 Takenori : 23:19 | トラックバック
2006年06月25日
libtheora 1.0 alpha7
6が出たと思ったら、libtheora 1.0 alpha7が出てた。
と言っても、目新しい機能はないよう。
前に作っていたプレイヤーに少しずつ手を入れてマシなものにしていくかといじっていたので、alpha7にして動かしてみた。(win32/theora_static.dsp にはなぜかcpu.c/.h とdsp.c/.hが入っていなくて、プレイヤー側のリンクでエラーが出たので、追加してからライブラリを作る必要があるみたい。)
CPU負荷などはmmx版と大差ない気がする。
投稿者 Takenori : 18:07 | トラックバック
2006年12月29日
ビデオオーバーレイは消える?
Windows Vistaではビデオオーバーレイは非推奨で、Aeroを使うとオーバーレイは使えないとか。
でも、実際はAeroを使用しなくてもビデオオーバーレイは使えないと言う話も。
Windows Vistaでは、ビデオオーバーレイの使用は諦めると言うことになりそう。
VMRを使えば良いとの事だが、VMRみんな使っているのだろうか?
WMVをサポートするためにやむなくVMRを吉里吉里2に実装したが、ここにきて奏功してきたかも。
再生環境を増やすのなら、XPまではオーバーレイでVista以降はVMRのようにモードを切り替えるのがいいかもしれない。
ただ、吉里吉里2では、静止画とのミキシングがしづらい。
DirectXのサーフェイスならサクサク行くんだろうが、吉里吉里2の場合は元画が変わるたびに変換が発生する。
テキスト表示時などは頻繁に変わるので、そのたびに変換が発生し重い。
それなら諦めてレイヤーモードを使うと言う手もあるが、そうなるとWMVは重過ぎて辛い。
テキスト描画をDirectX側でやるって手も考えたが、とりあえずは必要なかったのでやっていない。
・・・
ま、必要になったら考えるか。
今はとりあえずいい。
2008/01/06 追記:
オーバーレイ自体は使えるが、ハードウェアオーバーレイは使えないようだ。
ソフトウェアによってエミュレートされるらしい。
そして、オーバーレイでムービー再生した場合、等倍なら問題ないが、拡大などすると補間がかからず、ジャギーが発生して見辛くなるとのこと。
やはり、Vista ではオーバーレイを使わないほうがよさそう。
投稿者 Takenori : 23:08 | トラックバック
2007年01月20日
OpenMAX と GStreamer
DirectShowのようなものを組み込み機器で実現する仕様としてOpenMAXと言うものがあることを知った。
で、OpenMAXにはOpenMAX ILとOpenMAX DLがあり、OpenMAX ILはDirectShowのフィルタのようなものを実現するためのAPI仕様っぽい。
OpenMAX DLは、MPEGなどのコデックからハードウェアを利用するためのAPI仕様。
DirectX VAみたいなものか。
他にまだ確定していないようだが、OpenMAX ALと言う記述も。
ざっと見た感じだと、OpenMAX ILのみでは、アプリケーションから扱いづらいので、使いやすくするための仕様としてOpenMAX ALを作ろうとしているのではないかと思う。
たぶん、DirectShowのフィルタグラフにあたるのではないかと。
OpenMAX ILのサンプル実装がここにあるので、これを見ると少しイメージが湧くかも。
OpenMAXに準拠するといいかもと思ったが、今のところそれだとDirectShowのフィルタだけを作るようなもの。
実際に使えるようにするには、より上位部分の仕様を考えて作らないといけない。
そして、それがOpenMAX ALだとすると、中途半端に仕様に準拠したものが出来上がって、全体としてどうなの?って感じに。
ロイヤリティーフリーのオープンなAPI仕様として期待が持てるけど、普通に使えるようになるのはまだ先なんだろうか?
LinuxでDirectShowっぽいものとしてGStreamerと言うのがあるようだ。
GStreamer概要を見るとDirectShowみたいだ。
ライセンスはLGPL。
上のOpenMAXのサンプルにGStreamer pluginsって記述もある。
OpenMAX ILだけだと使えないから、GStreamerのElementとして実装して使えるものにするって感じなんだろうか。
で、思ったこと。
WinではDirectShowでLinuxではGStreamでいいんじゃないの?
もし、さらに適用範囲を広げるならOpenMAX。
OpenMAXで一本化できるのが理想ではあるが。
投稿者 Takenori : 22:17 | トラックバック
2007年01月21日
theoraのフレーム数
もしかしなくても、フレーム数を得るにはページヘッダーを最初から読んでいって、最後のページのヘッダーに書いてあるフレームを見ないとわからない?
シークも順番に読んでいって目的のフレームを探して、直前のキーフレームから開始しないとだめか。
やはり、最初にすべてのページを読んでキーフレームの位置をキャッシュしておいたほうが良いだろうか?
それとも、必要になった時に読むべきか。
最初にすべて読むようにして作ってみて、あまりにも遅かったら適時読むようにするか。
Oggコンテナメモ
RFC3533
Ogg Vorbisの成り立ち
投稿者 Takenori : 22:01 | コメント (2) | トラックバック
プレイヤーを分割
以前作ったTheoraプレイヤーをクラスを分割して、それなりに使えるようにしていくことに。
現在は、オーバーレイを扱うクラスとTheoraをファイルから読んでデコードしてサーフェイスに書き込むクラスの2つしかない。
とりあえず、再生できれば良いと作ったので、かなり適当な作り。
いきなり細かく分けていくと大変なので少しずつ分割していく。
とりあえず、直接freadとかで読んでいた部分をストリームクラスを作って、それを介して読むようにした。
次は描画側かな。
レンダラとアロケーターを作るか。
投稿者 Takenori : 23:15 | トラックバック
2007年10月20日
MPEG1デコーダーについて
MPEG1デコーダーを作る時の情報について書いておく。
トリケップス MPEG技術のCD-ROM版 を5年以上前に買った ( 書籍のほうが欲しかったが、当時すでに手に入らなかった ) 。
気付くとこの中の MPEG Video 技術の章は Web で公開されていた。
たぶん、MPEG1~2についてこの書籍が一番詳しいのではないかと思う。
ただ、この書籍を見れば作れるかと言うとそうではなく、細かいファイルフォーマットは完全には記述されていないよう。
細かい仕様については、JIS 規格の X4321 ~ X4323 を参照すれば載っている。
JIS 規格は、JIS 検索で数字打ち込んで検索すれば、閲覧できる。
でも、これだけで作るのはかなりしんどい。
MPEG1 ビデオデコーダーで BSD 系のライセンスで使えるものは、The MPEG Libraryとその元になった Berkeley MPEG player ぐらいしか知らない。
ただ、The MPEG Library はグローバル変数使っていたり、FILEポインタ依存だったり、使われていない関数があったりとだいぶ手を入れないと使いづらい。
まあ、コアとなるデータのパースや動き補償、IDCTなどは使えるので、一から作るよりははるかに楽。
MPEG1 オーディオデコーダーは適当なのが見付からない。
gst-fluendo-mp3 がBSD 系のライセンスだけど、MPEG1 Layer 3 のみっぽい。
MP3 はいらなくて、Layer 1 or 2 が欲しいのだが。
3 があれば、1 や 2 は何とかなるかな?
まあ、まだあまり調べていないので、オーディオデコーダーはもう少し調べる必要がありそう。
MPEG1 スプリッターのオープンソースなものは探していない。
MPEG1 System のパーサーは他と比べれば比較的楽に作れるだろうから。
ただ、シークは大変そう。
投稿者 Takenori : 01:03 | トラックバック
2007年10月27日
Theora と MPEG I
ある程度再生できるようになったので、プレイヤーをムービー再生エンジン で公開。
でも、MPEG I はブロックノイズ出まくりです。
動き補償辺りが怪しげ。
Theora は、バッファリングの効果か、ベータ2のおかげか、以前のように CPU 負荷が急激に跳ね上がることは少なくなってます。
バッファリングの枚数は別に何枚でもいいんですが、とりあえず5枚にしています。
内部構造的には、スプリッタとデコーダーだけ別になっていて、ファイルの入力ストリームやレンダラーは共通です。
ただ、現状フォーマットはYV12限定ですが。
そのうち、YV12 -> RGB32 変換は対応すると思います。
再生速度は DirectShow と同じようにレンダラーが握っています。
レンダラーは、アロケーターを持っていて、アロケーターはアロケートできる枚数に制限をかけています ( これが上のバッファリング枚数 ) 。
デコーダーは、レンダラーのアロケーターから確保したバッファへデコードが出来ると、そのバッファをレンダラーへ渡します。
レンダラーは、渡されたバッファをキューイングし、バッファに記録されているプレゼンテーション時間になると、そのバッファを画面に表示し、開放します。
バッファが開放されると、そのバッファは再びアロケーターで使えるようになります。
つまり、デコーダーは、アロケーターからバッファが確保できなくなるまでデコードし、確保できなくなると、レンダラーがバッファを開放するまで待ちます。
この構造により、デコーダーはバッファとして作られた枚数まで先読みすることになり、CPU負荷はある程度均等化されます。ただ、再生開始直後は負荷が高くなります。
再生してみるとわかりますが、Theora は思ったほど高負荷ではなくなっています。
これぐらいなら普通に使えそうです。
WMV も対応しようかなぁと思っていましたが、意外と Theora があれば大丈夫かもしれません。
MPEG I はまだ全然ダメです。
BSD系のライセンスで使いやすいのがあればいいんですが……
まあ、綺麗に再生できるようにして、MMX や SSE に対応し、メモリコピー周りを見直せば、OS付属のものよりも速くなるだろうと思ってはいます。
OS付属の MPEG I デコーダーは、パックドタイプの YUV しかサポートしていないので、YV12 が使えません。
そのため、YUV -> RGB24 が入っていて、少し重いです。
Theora 再生できるようにしたら、Vorbis に対応して音を鳴らしたくなってきた。
音を鳴らして、シークも出来るようにすれば、それなりにエンジンとして使えるなぁと。
MPEG I はぼろぼろだけど。
投稿者 Takenori : 01:21 | トラックバック
2007年11月07日
Theora のデコードをもっと速く その1
Theora と MPEG I で Theora の再生が軽くなっていると書いたが、 mplayer や VLC media player はもっと軽い。
この CPU 負荷の差はなんだ? ということで高速化に取り組むことにした。
まず、前回公開したものは MMX が有効になっていなかったようなので有効にした。
そうすると 30% ぐらい高速化される。
でも、これと比較しても mplayer はかなり軽い。
ついでに theora-exp にも対応したけど、負荷は大差なし。
ソースを見ていて気付いたのだが、最新のソースは theora-exp を旧インターフェイスでラップしているようだ。
なので、負荷がほとんど変わらないのは当然か。
後、当然のことながら theora-exp のインターフェイスでも使えるようだ。
負荷に差が出るとしたら、読み込みの部分と最終的な描画部分が考えられる。
最終的に オーバーレイ を使用して描画しているが、この辺りの扱いの違いで負荷が異なるのかもしれないと試してみる。
オーバーレイ 周りは大体ビデオカード側の話なので CPU には影響しないかと思いきや、オンボードのGPUの場合 ( と言うか自分のマシンで ) 、やり方によって負荷が大きく変わる。
VRAM だし、余裕があるからそんなに切り詰めなくてもいいやと大きい領域でコピーとかすると CPU 負荷に大きく響く。
で、初め オーバーレイ 周りは、プラマリサーフェイスを作って、オーバーレイサーフェイスを作って、デコード後の画像をメインメモリにコピーしてから、オーバーレイサーフェイスへコピーしていた。
これが初期の状態。
いろいろ見ていると オーバーレイサーフェイス が複数作れる環境があることを知った。
ならばと、メインメモリ の代わりに オーバーレイサーフェイス を複数作って、そこにコピーし、UpdateOverlay でプラマリサーフェイスへ反映するのが速いのではないかと思い、そうするとオンボードのマシンでは軽くなった。
オンボードでないマシンでは、そもそも複数の オーバーレイサーフェイス が作れなかったので、オフスクリーンサーフェイス を使い、BltFast でオーバーレイサーフェイスに反映するようにした。
でも、mplayer や VLC の CPU 負荷には及ばない。
そこで、VLC のソースを見てみた。
オーバーレイ周りは、サーフェイスオーバーレイのバックバッファを作って、そこにコピーした後、Flip しているようだ。
なるほど。
そんな手があるのかとやってみるが、オンボードのマシンでは重くなった。
なぜ?
よくわからないけど、そういうことのようなので、オーバーレイサーフェイス が複数作れる場合は、複数作って 、UpdateOverlay 、そうでない場合はオフスクリーンサーフェイスを使うことにした。
まあ、オーバーレイサーフェイス が複数作れない場合は、バックバファを複数持つのも手かもしれないが、いくつまで作れるのかが問題になるし、オンボードでない場合は大して気にすることもないかとそうした。
次は読み込み周りを疑う。
SHCreateStreamOnFile で IStream を得て、それを用いてファイルからの読み込みを行っていたが、シーケンシャルに読み込みを行う場合は、CreateFile で FILE_FLAG_SEQUENTIAL_SCAN を使えば、場合によってはかなりパフォーマンスが向上するらしいので、そうしたが効果なし。負荷に影響は見られない。もっと読み込み量が多い場合に影響するのだろうか。
で、再び VLC のソースを追う。
どうも 低レベルの open や read で読み込んでいる様子で、待ちが発生する場合はウェイトが入っているよう。
と言うことは、非同期にすればいいのかな? と ReadFileEx を使い、イベント待ちするようにしたが、遅くなったので止めた。
VLC のソースとは同じにしていないが、あんまり読み込みまわりは関係ない気がしてきたのでこれ以上は止めた。
結局、読み込みと描画部分では mplayer や VLC に追いつけなかった。
まあ、最終的にソースは全然違う形なのだが。
何かないかと theora の ヘッダーを追うと、コールバック関数を登録できるようだ。
登録した関数は、デコードが終わった直後に、デコードができたブロックを引数に入れて呼び出されるようだ。
それで何がうれしいかと言うと、デコード直後なのでキャッシュにのっている可能性が高く、高速化されるかもしれない。
実際、利用すると 2.5% ほど高速化された。
ただ、それでも追いつかない。
※ このコールバック関数には開始と終了行がブロック幅単位で渡されるので、8倍する必要があるのだが、ムービーの画像サイズが16の倍数でない場合は、はみ出た部分も関係なく渡されたりするので、メモリのアクセス違反が出ないように画像サイズを超えていないか確認する必要がある ( 800x600を再生した時これでエラーが出て気付いた ) 。
もしかしたら、MinGW の最適化がすごいのか? ということで、 mplayer のところにある MinGW の環境を落としてメイクすることにした。
落としてきた環境には既に libtheora.a などが入っているので、それを使うことにした。
とりあえず、libtheora.a を使って VC でビルドするが、高速化されない ( __allocaがないとか言われたので、libgcc.a をくっつけて無理やりビルドした ) 。
全てを MinGW でコンパイルしないとだめなのかと、MinGW でコンパイルを通そうとする。
基本的に Win API 直叩きで書いているので、それほど労せずコンパイルは通った ( ATL の CComPtr 部分のみ使わないように修正した ) 。
が、起動してすぐに落ちる。
よくわからない。MinGW がよくわからない。
よくわからないので、libtheora についてる dump_video を -f オプションつけてデコード時間を計ってみることにした。
VC と大差なし。
何でだろうか?
いろいろ調べて、MinGW でコンパイルしたものが起動するようになった。
でも、やはり速くはならない。
とりあえず、起動するようにするのに以下のようなことをした。
リソースは windres でコンパイルできる ( 引数に --input-format=rc --output-format=coff をつける )
リンクは gcc に"-mno-cygwin -mwindows"を付ける ( -mno-cygwin は要らないかも )。
ライブラリとして -lmingw32 -lstdc++ -lgcc -lmoldname -lmingwex -lmsvcrt -lkernel32 -lwinmm -luser32 -lshell32 -lmingwthrd を付ける ( 本当は要らないのがいっぱいあるかも ) 。
VC でビルドしたのが 380 KB なのに MinGW のは 2MB とでかいのは気になるが ( 後に strip ○○.exeってやれば400KBになることがわかった。でも、速くはならない ) 。
しかし、MinGW でも普通にウィンドウズアプリ作れるんだなぁ。
ちょっと感動。
libtheora.a と libogg.a を使った時に気付いたのだが、libogg.a にあるはずの bitwise.c の中の関数がないとリンク時に怒られる。
その時は、なんでないんだろう? と思ったけど、bitwise.c をくっつけてビルドして通した。
でも、もしかして bitwise.c の中の関数を高速化しているのか? と思い、調べることにした。
bitwise.c の中にはビット単位での読み出し用の関数が入っているので、この部分の高速化はかなり効くはずだ。
呼び出し回数をカウントしてみると、1フレーム中に数千~数万回呼び出される ( ちなみに、libtheora の中からは oggpackB_readinit, oggpackB_adv, oggpackB_read, oggpackB_look, oggpackB_bits, oggpackB_read1 の6つの関数が使われている ) 。
他のと同じように bitwise.c の中には、参照するだけ、参照してポインタを進める、ポインタを進めるだけの3種の関数がある。
てことで、単に関数を間接的に呼び出してたりするだけだったりするのとかあるので、インライン化することにした。
でも、C なのでマクロか直埋め。
が、わずかに高速化するもののたいした効果なし。
関数内を根本的に変えないとだめなのか、それともここはあんまり関係ないのか。
とりあえず、大変なので放置。
( 後で気付くが、mplayer では tremor と言うライブラリが使われており、その中に同じ関数が入っている。でも、それに差し替えても速度は大差なし )
libogg の中で、page や packet の読み込みを行っているが、見るとメモリのコピーなどをよく使っているように見える。
と言うことで、これ ( demux ) を自分で作ることにした。
初め、packet さえあればいいと思っていたけど、segment の境界もきちんと認識する必要があると気付き、少し非効率な作りになったが、それでもわずかばかり高速化した。
ただ、ヘッダー付近でうまく読み込めてないらしく、最初に少し画像が乱れるので直す必要がある。
と言うか、segment を考えて作り変えた方が良さそう。
でも、そんなに高速化しないのがなぁ。
と言うことで、ここは今元通りに libogg を使ってる。
しかし、mplayer などに全然追いつかない。
かなり長くなったので、ここでエントリーを分割。
つづく。
投稿者 Takenori : 02:31 | トラックバック
Theora のデコードをもっと速く その2
libtheora そのものに手を加えずに、他に高速化されそうな箇所は、malloc 系と memcpy, memset ぐらいか。
realloc など使われているので、もしかしたら高速化できるかもしれないと呼び出し回数を調べてみる。
malloc, calloc, realloc は合計すると8000回ぐらい呼び出されているようだが、回数が増えるのは最初だけで、以降は変化なし。
realloc は数回しか呼ばれていない。
サイズが 4 とかで呼ばれていたりするのが少し気になるが、途中から呼ばれないとなるとそれほど高速化には寄与しなさそうだ。
--- malloc について脱線
malloc のアルゴリズムにもよるが、malloc は意外と遅い。
まあ、遅いとは言っても、最近のPCではかなりの回数コール ( 数十万回とか数百万回 ) しないとあんまり影響ない。
ただ、サイズ固定でメモリ確保する malloc のようなものと malloc を比べた場合、サイズ固定ならば比較にならないぐらい速い。
この辺りの事について一度書こうと思って、計測結果をメモしていた気がするが見当たらないのでまた今度にする。
--- 脱線終わり
malloc などで確保されるメモリのサイズの偏りを調べて、小さいサイズ用に固定サイズ版 malloc を作ってもいいけど、最初だけじゃあなぁ。
余計なヘッダがつかなくなるのと断片化が回避できそうなのと、キャッシュ効率が上がりそうな気はするけど、それほど速くならない気がするのでここはそのままに。
で、memcpy と memset 。
mplayer のソースを見ると fastmemcpy とかあって、高速化に寄与しそうだと思い少し検索してみると、VC の memcpy などはかなり高速らしい。
Visual Studio をインストールしたフォルダの VC/crt/src/intel の中にソースも入っていると言うことで見てみる。
あきらめた。
memcpy とかはいいや。
たぶん、VC のが速い。
ここまでの結果と比べても、mplayer の方が倍ぐらい速いように見える。
なんだろう。
追いつける気がしない。
VLC の中には libtheora を使っているソースがあるので、libtheora を使っていると思っていたが、libtheora のソースが違うんじゃないのか? と思えてくる。
ソースを見ていて気付いたが、libavcodec の vp3.c の中には theora のデコード用のコードがある。
で、ここを見ると、別に書き起こされたような記述が。
もしかして、こっちが使われている?
と言うことで、libavformat / libavcodec に対応することにした。
で、対応したのだが遅い。
libtheora に比べて半分以下の速度しか出ない。
たぶん、使い方が悪いのだろうと思い、VLC や mplayer のソースを見るがそれほど変わったことをしているようには思えない。
何だろう? よくわからない。
VC2003 から VC2005 に切り替えるとどれぐらい速くなるのだろうと思い、VC2005 でビルドすることにした ( VC2003 のが使い慣れていて使いやすいし、sprintf とかでセキュリティがどうたらとあまりうるさく言わないので、今まで主にVC2003を使っていた ) 。
5% ぐらい速くなった。
速い。
VC2005 の最適化すごいなぁ。
で、以前から気になっていたのだが、VC2005 にはプロファイルをとって最適化する機能がある様子。
メニューの デバッグ → ガイド付き最適化のプロファイル にはよくわからないのが並んでいる。
インストルメントが怪しいということで実行する。
ビルドされた。
次に「インストルメントまたは最適化されたアプリケーションの実行」をしてみる。
アプリが起動した。たぶん、ここで実際に使うのだろうとデコードしてみる。
終わった後、アプリを終了して「最適化」を実行してみる。
何か最適化されたものができたっぽい。
実行してみる。
10% ぐらい速くなった!
すげー。プロファイルを使った最適化すごい。
勘で使ったんだけど、問題なかったようだ。
で、これで Athlon マシンで比較してみる。
かなり肉薄している気がする。
Core 2 Duo の方ではまだまだだけど。
でも、やはり libtheora なのかなぁと思い始めた。
後、VC2005 は積極的に使ったほうが良さそうだと思った。
まだつづく。
投稿者 Takenori : 03:32 | トラックバック
Theora のデコードをもっと速く その3
高速化版 IJG JPEG library のIDCT を持ってこれないかと考えた。
ソースを見てみたが、すんなりとは行きそうにない。
今度は、libavcodec の vp3dsp_sse2.c のはどうか? と考えた。
Athlon に比べて Core2Duo の方が差が激しいのは、SSE2 によるものではないかと思ったので、SSE2 を使うコードなら速くなるのではないかと。
こちらはかなり似通っていたので、簡単に持って行けそうと言うことで、とりあえず差し替えてみる。
何事もなかったかのように再生できる。
いきなりうまくいったので、なんだか不審に思いその箇所をコメントアウトしてみる。
絵がぐちゃぐちゃになった。
ちゃんとそこを通っているようだ。
で、肝心のCPU負荷はと言うと、大差なし。
これではだめか。
VLC のソースを見ていると、libtheora に対するパッチが入っていたので当ててみる。
見た感じ、コンパイルオプションとかその辺りだが効果があるかもしれない。
結果変わらず。
mplayer を見てみてると _ilog に defined in many places in theora/lib/ とコメントされている。
libtheora の中では、oc_ilog で int ret; for(ret=0;_v;ret++)_v>>=1; return ret; と実装されている。
と言うことで、これを _BitScanReverse を使うようにしてみた。
結果変わらず。
libtheora のヘッダーで OC_SQRTFなどは sqrt をキャストする形になっている。
これを sqrtf などに変えてみた。
結果変わらず。
やはり、libavcdoec/format なのかなぁと思ったが、mplayer で再生した時よく見ると、libavcdoec のは選択されていない様子。
あれ? やっぱり違うのかと思って、libavcdoec を作る時に libtheora を使うようにしてみた。
速くなった。
直に使うよりは遅いが、libavcdoec に入っているのを使うよりかなり速い。
libavcdoec は消えたか……
プロファイラが使えるといいのになぁと思いながらいろいろ調べている時、VTune を使っているブログ記事を見た。
便利そうだ。
いいなぁ。
なんかないかと探すと、GNU には gprof と言うものがあるようだ。
( 参考 : GNUプロファイラーによるコード処理速度の向上 )
使えるかもしれない。
でも…… と気付く。VC2005 もプロファイルして最適化できるんだから、そのプロファイル結果を見ることはできないかと。
使い方があった。 Microsoft Visual C++ 2005 での PGO。最適化に関する説明もある。
なるほど、コマンドラインでやればいいのか。
その上位いくつかをピックアップすると以下のような感じ。
| 関数名 | entry count | static instr | dynamic instr | % total | run total |
| _oc_dec_frags_recon_mcu_plane | 150864 | 139 | 5143602006 | 13.2 | 13.2 |
| _oc_dec_ac_coeff_unpack | 396018 | 126 | 4602181872 | 11.8 | 25.0 |
| _theora_look | 116339060 | 164 | 4428304982 | 11.4 | 36.4 |
| _oc_frag_pred_dc | 24147386 | 124 | 3984914480 | 10.2 | 46.7 |
| _theora_read | 76286536 | 88 | 3380383804 | 8.7 | 55.3 |
| _oc_huff_token_decode | 101515220 | 26 | 3284889700 | 8.4 | 63.8 |
IDCT 周りはインラインアセンブラがあるので MinGW でコンパイルしているためか入っていない。
そこも結果が見れるようにSIMDの関数版に置き換えて計測してみたいところだが、それはベータが取れてからかな。
でも、やはりビットの読み込み部分はかなりの率を占めているようだ。
他のは、中に手を入れないとどうもならないよなぁ。
投稿者 Takenori : 17:30 | コメント (2) | トラックバック
Theora のデコードをもっと速く その4
「Windows の CPU 負荷は当てにならない。どうも Windows はプロセス時間をミリ秒単位でカウントしてるらしく、タスクが消費した一回のタイムスライスが 1ミリ秒未満だとカウントされない。」 と言う話を聞く。
何ですと!?
確かに、Core 2 Duo では、mplayer で再生した時 CPU 負荷が 0% をさしていることが多く、ありえないぐらい速いなぁと思っていたのだが、あれはうそだったのか?
と言うことで、もっと負荷の高い動画で試すことにした。
Full HD サイズの theora 動画を作って再生。
mplayer や VLC では絵が止まりまくりでまともに再生できない。
音を止めても、絵がよく止まる。
CPU 負荷は 100% を振り切っているようだ。
対して、自分のはかろうじて再生できている。
音に対応していないので、その辺り気にせずデコードしているせいもあるが、バッファなどが効いているのか遅くなっているのはあまり感じられない。
CPU 負荷も比較するとだいぶ軽い。
なんか雲行きが怪しくなってきた。
今度はPen III M 866MHz のマシンで 640x480 の動画を再生してみた。
やはり、mplayer よりも軽い。
なんと言うか…… CPU 負荷に騙されてがんばっていたのか……
より正確な負荷を調べるすべはないかと探すと、timeit コマンド と言うものがあるようだ。
timeitコマンドでアプリケーションの実行時間を測定する
と言うことでリソースキットを入れて計ってみる。
約105秒の動画を mplayer で再生してみたところ…… Process Time: 0:00:16.203 と出た。
描画をカットして、デコードのみするようして時間を計っていた時、自分のは 8秒を切るぐらいだったのだが。
もしかして、期待できるのか?
ただ、上のは音が入っているので、-nosound オプションをつけて計ってみた。
0:00:14.937 と出た。
1秒ちょっとぐらいが音のデコードに使われているのか。まあ、そんなものかな。
で、自分のでちゃんと描画もするようにして計ってみる。
Process Time: 0:00:09.359 !!
40% ぐらい速い。
過去のと時間を並べてみると……
Process Time: 0:00:14.640 - 156% - 最初のバージョン
Process Time: 0:00:10.843 - 116% - MMX を有効にしたもの
Process Time: 0:00:09.359 - 100% - 今のやつ
パーセントは今のを 100% とした場合の数値。
MMX を有効にした後のからは大して速くなってないなぁ。
まあ、結局なんだかんだで CPU 負荷見て速くなってないなぁと元に戻していたりしたので、1個1個 timeit で計測しながらやると更なるスピードアップが望めるかもしれない。
まあ、それはベータが取れた後かな。
そうすれば、中に手を入れつつ最速のバイナリが作れるかもしれない。
と言うことで、Theora のデコードをもっと速くはいったんここまで。
投稿者 Takenori : 17:56 | トラックバック
Theora のデコードをもっと速く その5
気になることがあったのでちょっと追加。
MMX対応後のやつの Bytes Written: を見ると 105585 と妙に少ない。
新しいのは、549982 と多い。
そこでなくとなく Flip を試してみた結果、Process Time: 0:00:08.703 - 93% とだいぶ速くなった。
ただ、Bytes Written: が 243383 から 493162 に倍増した。
ディスク書き込みなど行っていないのだが、これは何なのだろう……
オンボードで重くなるのはこの辺りも関係しているのかな?
ふと、MPlayer on Win32 のをバイナリを取ってきて計ってみた。
Process Time: 0:00:07.359 - 79%
速い。やっぱり負けてる。
Athlon 64 X2 3800+ の ビデオがオンボード ( NVIDIA GeForce 6100 ) のほうでも計ってみた。
こちらは、上のページの athlon 最適化版を使用した。
Process Time: 0:00:17.000 - 61% - mplayer-athlon
Process Time: 0:00:37.765 - 136% - 最初のバージョン
Process Time: 0:00:31.046 - 112% - MMX 版
Process Time: 0:00:27.828 - 100% - 今のやつ - 複数の overlay が使われる
Process Time: 0:00:47.015 - 169% - Flip 版
Process Time: 0:00:15.921 - 57% - 描画部分をカットした場合
Core 2 Duo E6750 + NVIDIA GeForce 8600 GT の方ももう一度記載。
Process Time: 0:00:07.359 - 79% - mplayer on win32
Process Time: 0:00:14.640 - 156% - 最初のバージョン
Process Time: 0:00:10.843 - 116% - MMX を有効にしたもの
Process Time: 0:00:09.359 - 100% - 今のやつ - offscreen が使われる
Process Time: 0:00:08.703 - 93% - Flip 版
Process Time: 0:00:07.328 - 78% - 描画部分をカットした場合
オンボードかどうかによってかなり違うなぁ。
後、Athlon マシンは MMX の効果があまり得られていない。
ビデオ側の処理が重く、それによって隠蔽されているのか。
Overlay の扱い方によって、かなり速度が変わることは間違いなさそうだ。
mplayer の中には専用のドライバなどが入っていたりするので、その辺りには力を入れてそうだ。
でも、Overlay は、Vista では使えないと考えておいたほうが良いと思うのでどうしたものかなぁ。
Direct3D を使うようにして、それでチューニングしたほうがいいのだろうか。
投稿者 Takenori : 22:41 | トラックバック
2007年11月08日
Dirac とか
Dirac video codec を試してみた。
落としてきて make してエンコードしてデコードしてみる。
720x576 が Core2Duo E6750 で 10 FPS 。
重い。
とりあえず、ムービー再生エンジン のページに Dirac 0.8.0 を MinGW で make した dirac_decoder と dirac_encoder を置いておく。
使い方などは、Dirac0.6のエンコーディング実験。 のページを見るとわかりやすいかも。
theora 動画を VLC とも比較してみた。
Process Time: 0:00:13.093 - 140% - VLC media player 0.8.6c
Process Time: 0:00:09.359 - 100% - 今のやつ - offscreen が使われる
Process Time: 0:00:08.703 - 93% - Flip 版
VLCとなら張り合えるんだなぁ。
Xiph.org Test Media というのがあると教えてもらった。
ロスレス ( PNG ) で圧縮された連番静止画の動画が置いてある。
フルHDサイズ ( 1920x1080 ) だと、21GB 。。。 でかい。
640x360 の方を使ったほうがいいかな。それでも 3.3GB だけど。
で、PNG から Theora に変換するのに便利なように、ムービー再生エンジン のページに png2theora を置いておく。
これは libtheora についているんだけど、 MinGW でコンパイルしようとしたら、scandir がないと言われてうまくいかなかったから、scandir を別に作って中身を FindFirstFile にしたものにしている。
ただし、ファイル数の上限は 32768 個まで。面倒だったから固定にした。
後、パラメータの switch case のところで break が抜けている箇所があって、おかしかったので直した。
上のページにもあるけど
png2theora -o out.ogg -v 6 -f 30 -F 1 %05d.png
のように使う。%..の箇所は書式指定。連番の画像を指定できる。
引数を与えなかったら簡単な使い方が出る。
中身は、libpng で読み込み、YUV 変換、theora へエンコードとなっている。
複数スレッドに分割すればもう少しエンコード速くなりそうだと思うけど、実験用には十分。
投稿者 Takenori : 18:52 | トラックバック
2007年11月09日
Tremorって?
libogg の時に mplayer のソースで出てきた Tremor 。
ふと何か気になったので調べた。
Tremor 。
つまり、浮動小数点演算を使わない Vorbis デコーダーか。
よく見ると Vorbisのページ にもちゃんとあるね。
Vorbis は、こっちの方が速かったりするのかな?
Wikipedia を見ると組み込み ( ARM? ) 向けのように書いてあるが。
投稿者 Takenori : 16:52 | トラックバック
2007年11月19日
なんとか MPEG I の再生が綺麗に
MPEG I の再生がおかしいのを何とかすることにした。
動き補償周りが怪しいとは思うものの、すぐには問題の箇所を特定出来なかった。
いろいろと OFF にして絞り込もうとしたけど、わからず机上で追うことにした。
そのついでに、その周辺のソースの整理とコメントの日本語化も行った。
JIS のドキュメント見つつ、ソースも追いながら。
で、不具合の原因は極めて単純で、8 回ループすべきところが、4 回になっていたこと。
元のソースはループの展開を行って、少しでも速くしようとしていたようだけど、それほど効果も見込めないし、読みづらいのでその箇所は直していた。どうやらその時にミスっていたようだ。
そのようなループの展開を行っているのは1箇所ではなくて、何箇所もあって書き方も数通りあったので、見つけづらかった。
これで綺麗になったと思いきや、時々おかしなブロックが出る。
そのブロックは、単色だったり縞々だったりするので、IDCT 周りが怪しいと踏んだ。
IDCT のソースはほとんどそのままなので、その前段階のハフマンデコードをまず疑ってソースを追うもわからず。
IDCT の部分を調べることに。
IDCT の中に ORIG_DCT というデバッグオプションがあったので、ON にしてみた。
綺麗になった。
えっ?
中を見ると、前段階のハフマンデコードで最後に書き込んだ DCT 係数の位置によって事前計算したテーブルを参照する位置を変えて IDCT を行うコードに切り替わるかどうかの違い。
どうもこのテーブルを使うバージョンがおかしいようだ。
何がおかしいか中を追うのは面倒なので、テーブルバージョンを通らないようにした。
これで綺麗に再生できるようになった。
ただ、ファイル終端付近の処理がおかしいようで、ファイルによっては最後の方で落ちてしまうことがある。
まあ、これはわかりやすいので簡単に直るはず。
後、現バージョンでは MPEG I デコードがすごく重い。
これは、MMX や SSE2 を使えばかなり改善されるはず。
とりあえず、Intel AP-945 (PDF) の イントリンシック を使った IDCT に切り替えると、処理時間の 28.4% も占めていた IDCT が、0.1% になった。
すごく速い ( ただし、これをそのまま使ってもいいのかどうか不透明なので、最終的には別のものになると思う ) 。
これで、処理時間のトップだった IDCT が圏外に消えて、動き補償がトップに。
動き補償の部分は、単純にブロックをコピーしたり、前後のフレームのある位置のピクセルをピクセルごとに足して2で割って四捨五入したものをコピーしたりするが、SSE や SSE2 には、この足して2で割って四捨五入というこのための命令があったりするので、ここもかなり改善されるはず。
また、Intel の 日本語技術資料のダウンロード ページには、このような処理をどうするかと言った資料があるのでやりやすい。
投稿者 Takenori : 17:46 | トラックバック
MPEG I デコードでもとのソースから変えているところ
かなり初期の段階で、C 言語から C++ に書き換えている。
これは、マクロ関数を手軽にインライン関数にしたかったのと、グローバル変数を廃してクラスにしたかったから。
ただ、元の構造を引きずっていていまいちな部分もあるので、この辺りは直したいところ。
もともとはデコード用の関数があって、最初に1回それを呼んだら画像の幅などの情報をシーケンスヘッダから取得してくれて、以降はその関数を何度も呼ぶことでデコードされる。
ただ、1回呼べば1フレーム進むと言うわけではないのと、しばしば Unknown start code. とデバッグ出力に出るので気持ち悪かった。
と言うことで、この部分をかなり異なる形にした。
まず、最初に呼ぶ関数を分離して、別関数にした。
この関数で MPEG I Video ストリームかどうか判定される。
それ以降は、デコード用の関数をコールする。
基本的に1度呼べば1フレーム進む。
これで、この部分はすっきりした。
Unknown start code. もでない。
他は、前出のループ展開部分をループに戻すように、可読性を損ないそうでたいした効果もなさそうな箇所を見やすいように直している。
このような処理で局所的なものはほとんど直したが、似たような処理で共通化できそうに思う箇所はまだ残っている。
ついでに、元のソースでは半画素単位の動き補償で処理を簡略化していた部分を、きちんと行うようにした。ただ、あまり画質が向上したようには感じないので、あまり意味のない処理なのかもしれない。
後、コメントも日本語にしたりしている。
基本処理構造はほとんどそのままだけど、細かい部分ではかなり変わっている。
綺麗に再生できるようになったので、これからさらに変わると思う。
後、当然 MPEG I System から Video ストリームを切り出すスプリッタも追加されている。
投稿者 Takenori : 18:15 | トラックバック
Ogg ( Theora + Vorbis ) で音が出るように
やっぱり音がないとさびしいということで、音を鳴らすことにした。
今のマシンには HD Audio が付いているので、それが使えないかなぁと思ったけど、どのように使うのか調べてもすぐには見つからなかったので止めた。
DirectSound や OpenAL、 ASIO などどうするか考えて、とりあえずは DirectSound でいいやと DirectSound にした。
昔、DirectSound を使う何かを書いたような気がするけど、見付からなかったのでサンプルをベースに書き起こした。
ストリーミング再生のサンプルは、イベント通知があると、WAVE ファイルから読み込んでからバッファに書き込んでいるけど、ムービーでは直接読めないので、バッファへの書き込み関数だけ提供して、バッファに書き込めるかどうかの判定や、無音でのフィルは外に出した。
外と言っても、オーディオレンダラーというのがいて、それで処理するんだけど。
オーディオ側も、ビデオと同じようにサンプルのアロケートによってデコードの進み具合を調整するようになっている。
最初は、プチプチ言ってすぐに鳴り止んでなんだと思ったら、サウンドのループ再生を指定していなかった。
だから、バッファを確保している1秒ぐらいで停止してしまっていた。
で、ループするようにしたら音は鳴るんだけど、まともに再生できていない。
ビデオとオーディオのスレッドが共通なので、Ogg ファイルでのインターリーブのされ方によって、オーディオが間に合わないようだ。
0.5 秒分ぐらい先にオーディオを詰めておいてくれればまともに鳴るのだが、そのようにはなっていない。
と言うことで、やはりオーディオのスレッドを分離することにした。
分離すると、libogg は少し扱いづらいので、Ogg から読む部分は以前自分で作ったものを直して、ビデオストリーム、オーディオストリームと派生して、それぞれのストリームで読めば、そのパケットが得られるようにした。
で、うまく鳴るようになったのだが、Release ビルドにすると音か絵のどちらかが止まってしまう。
なんだろう? と考えていて、なんかうまくならないと書いた時に気付いた。
IStream を共通にしているので、別スレッドにするのなら、シークした後からリードするまでをクリティカルセクションなどで保護しないといけない。
でないと、その間でスレッドスイッチが起こると期待した位置から読めない。
と言うことで保護するようにした。
が、絵が遅れる。
ロックされている期間が長すぎるのか……
クリティカルセクションを使う前のデバッグバージョンではうまくいっていたのだが……
と言うことで、IStream を 2つ作ることにした。
シーク位置などは、やはり IStream に覚えてもらっていた方が手軽。
で、うまくいった。
でも、かなり釈然としない。
この部分に関してはもっと検討する必要がありそうだ。
後、現在 Ogg からはパケット単位で読むようにしているが、これはセグメント単位にした方が良さそうだ。
パケットは、複数のセグメントから構成されているが、theora のデコードはセグメント単位で行われる。
なので、一気にパケット単位で読み込むのではなく、セグメント単位で読み込んだ方がキャッシュ効率が上がり高速化が少し見込めるのと、読み込みでロックする期間が短くなるので、音と絵の同時デコードがやりやすくなるはずだ ( 今までの感覚では、読み込みは一気にやった方が速いような気がするが、どうも少しずつ ( 処理単位で ) 読んだ方が速いようだ。OS の HDD からの読み込み時のキャッシュが賢いのか、そこはそれほど気にする必要はなさそう。とは言っても、ディスクアクセスが頻発している時は引きずられるので、何か考えた方が良いとも言えるのだが。まあ、ここも検討する必要がある )。
他に、フォーカス移動したら音が止まってしまうのが気になったので、調べるとバッファ作る時に DSBCAPS_GLOBALFOCUS フラグをつけないといけなかったようだ。
これをつけると、フォーカスがなくても音が鳴る。
投稿者 Takenori : 18:55 | トラックバック
Vorbis のデコーダ
Vorbis は、オフィシャルのもの以外に高速化版がある。
これを使えば速くなるんだろうけど、SSE 用、SSE2 用、 SSE3 用とバイナリが分離しているのが扱いづらい。
くっついているのでは、wuvorbisfile があるけど、こちらで出ているインターフェイスは vorbisfile のもので、ogg ( theora + vorbis ) をデコードする時に使うメソッドは公開されていない。
オフィシャルのものを使うか、バイナリが分離しているのを使うか……
自分でそれらのパッチを取り込んで、ひとつのバイナリにしてしまうというのもありといえばありか。
他にTremor も試してみたいとは思う。
整数演算のみなら、MMX 化なんかも出来るんじゃないかなぁと思ったりする。
前出のは、SSE 用だし。
まあ、とりあえずはオフィシャルのものをそのまま使うことにする。
投稿者 Takenori : 21:13 | トラックバック
Direct 3D を使って描画するように
オーバーレイで常に最前面だと扱いづらいのと、画面サイズ以上の動画だとうまく更新されていなかったので、それらに対応するのならと、Direct 3D を使って描画することにした。
ソースコードは VMR を使って描画していたのを原形にして、子ウィンドウを作る部分などをなくして、VMR 依存の部分を書き換えた。
で、動かすと GeForce 8600 では、YV12 フォーマットのテクスチャは作れないようだ。
そうなの? ということは、VMR のはどうなっていたのだろうと確認すると、VMR 側が X8R8G8B8 で要求してそのフォーマットでテクスチャが作られている。
DirectX VA で変換されているんだろうか?
でも、まあそういうことなら X8R8G8B8 でテクスチャを作る。
YV12 から RGB への変換は、ビデオカードがサポートしていれば、単にコピーすれば変換してくれるので、大して気にすることではないはず (
IDirect3D9::CheckDeviceFormatConversion で確認して、IDirect3DDevice9::StretchRect でコピー ) 。
で、結局 YV12 フォーマットのオフスクリーンサーフェイスへデコーダに書き込んでもらい、それを描画前に X8R8G8B8 フォーマットのテクスチャにコピーして、そのテクスチャを板ポリゴンに貼って描画するようにした。
まあ、元々ビデオ画像を表示しつつ何か他のものを描画するために、一度テンポラリのテクスチャにコピーしてから描画しようと考えていたので、結果的には考えていた通りになった。
ただ、出来るのならアロケーターにすぐに戻さず次のフレームまでサンプルを保持することで、そのサンプルをテンポラリとみなしてコピー回数を抑えようと考えていたけど、それは出来ないことになる。
ま、色変換を CPU でやるよりはマシなので仕方ない。
UpdateSurface / UpdateTexture を使って、D3DPOOL_SYSTEMMEM で作ったサーフェイスをビデオメモリ側にコピーすると DMA を使ってコピーされるかもしれないと思って、試そうとしたんだけど、YV12 フォーマットで D3DPOOL_SYSTEMMEM にサーフェイスを作るとサイズがおかしい。
どうも輝度プレーン分しか確保されていない様子。
デコード時の色差プレーンのコピーでメモリのアクセス違反で落ちる。
で、とりあえず高さを1.5倍して無理やり色差の分も確保されるようにして、UpdateSurface してみると色差にごみが入っている。
輝度は正しく入っている様子。
何だろう? ドライバのバグ?それとも、使い方が違うのだろうか?
まあ、なんにせようまくいかないので、とりあえずはこの部分について深く追求しないことにした。
システムメモリのサーフェイスの方がより速く書き込めるので、コピーが DMA なら CPU 負荷を低減できる可能性があるので、後々より高速化するために調べるかもしれないが。
で、オーバーレイから Direct 3D に代えて CPU 負荷を見た感じ、少し増加している気がする。
ちゃんと計ったわけではないので、わからないけど。
ちなみに、オーバーレイを DirectX 2 から DirectX 7 のにしたら少し遅くなった。たぶん、使う構造体などのサイズが大きくなっているのでその辺りかなぁと思ったりするが、詳細はわからない。
投稿者 Takenori : 22:23 | トラックバック
2007年11月20日
音側から時間を取得
音がない時は、timeGetTime を使用して時間を取得し、画像の表示時間まで待っていたけど、音を鳴らすようにしたということで、音を鳴らす時は IDirectSoundBuffer8::GetCurrentPosition を使って時間を得ることにした。
これで音と同期が取れるようになっているはず。
内部的には、タイムキーパーにリファレンスクロックオブジェクトを渡せば、それが使われるので、時間を得る方法は何でも良い。
デフォルトは timeGetTime を使うようになっている。
描画を Direct3D にして、Vorbis の音を鳴らすようにして、MPEG I の絵がまともになったものをムービー再生エンジン に追加した。ovplayer_d3m.zip がそれ。
後、シークに対応して、動画の最後の方をちゃんとすれば、とりあえず Ogg 動画については最低限の機能はそろうかな。
MPEG I 側は、Audio がないので、それを何とかしないといけないのと、重いのを解消しないといけないが。
投稿者 Takenori : 00:01 | トラックバック
2007年11月26日
高速化版 JPEG Library から IDCT を
Intel AP-945 ( AP-922 ) の IDCT はそのまま使っていいのかどうか不透明なので、IJG JPEG library 高速化版 の IDCT を アセンブラ から イントリンシック を使ったCへ書き換えることにした。
で、初めはちまちま書き直していたんだけど、ほとんど SSE2 の命令で出来ているから、これを単なる正規表現で置換すれば、ほとんど終わるんじゃないか? と思って perl でスクリプト組んで変換。
変換できていないものを加えて変換と繰り返してほとんど変換できた。
SSE2 でない部分や正規表現書くのが面倒なところは手で直した。
で、出来たと思ったら、間違って AAN 版の DCT を書き換えてた。
以前一度あたりをつけていて、確かこれだと思って書き直していたんだけど、勘違いしていたようだ。
DCT があっても仕方がないので、今度は IDCT を書き換えた。
で、動かしてみたのだが、画像がぐちゃぐちゃ。
どこか間違っているようだ。
何か後半の転置が違うような気もする。
IJG JPEG library 高速化版の IDCT では、同時に逆量子化を行っているが、MPEG のは分離しているのでそこは省いている。
そうこうしているうちに気付く。
AAN 版じゃなくて LLM 版を使わないといけないことを。
AAN とか、LLM と言うのは、IDCT のアルゴリズムの種類で、基にした MPEG のソースでは LLM の IDCT が使われている。
LLM に比べと AAN はかなり高速らしいのだが、精度が低いらしい。
まあ、AAN 版もあったらいいなと思うが、とりあえずは LLM 版が欲しい。
で、LLM 版に取り掛かろうと思ったけど、その前に Theora のインラインアセンブラをイントリンシックで書き換えようと心変わりしたので、そちらを先にすることにした。
投稿者 Takenori : 22:48 | トラックバック
2007年11月27日
Theora のインラインアセンブラをイントリンシックで
Theora では主にIDCT、動き補償、デブロッキングフィルタで MMX が使われている。
一番面倒くさそうな IDCT は後回しにして、一番簡単な動き補償から取り掛かった。
nasm のアセンブラと比べて、gcc のインラインアセンブラは引数の順が逆。
最初は、かなり間違えそうになる。
で、そのまま直していたんだけど、かなり読み辛いのでCのソースと対比しながら、Cのソースをベースにして書き直した。
動き補償が終わったので、次はデブロッキングフィルタ。
同じようにまずはアセンブリのソースを見ながら直す。
で、次にCのソースを見ながら…… と思ったら、処理が明らかに違う。
詳しく見てみると、Cのソースはテーブルを使うようになっているが、MMX 版はテーブルを使わずに直接計算している。
なんてことだ。
仕方ないので、読み辛いアセンブリソースをそのままCにしたソースとコメントを頼りに見やすいように直す。
が、この部分は元々というか、MMX のせいでと言うか読み辛い。
比較命令が使われているせいだ。
a > b に相当する MMX の _mm_cmpgt_pi16 などを実行すると条件が成立するところはすべて 1 に、そうでないところは 0 になる。
で、この結果をマスクとして使って分岐処理を実現する。
つまり、b >= a の時、a を 0 にしたければ次のようになる ( Cでほぼ等価な処理を書いた場合 )。
m = a > b ? 0xFFFF : 0;
a &= m;
MMX ではこうやって書かないといけなかったのか。と知った。
でまあ、足し算とか引き算とかあるわけだけど、その場合は引く値側をマスクしてから引いたりする。
読み辛いことこの上なし。
仕方ないのでコメントで補足というか、仮想コードを併記しておく。
最後に IDCT 。これも同じようにアセンブリのソースをと思ったが長いので、また置換のスクリプトを書くことにした。
で、置換して、そこから直そうとしたが長いので、Cのソースから直接書き起こすことにした。
ただ、大まかな処理ブロックはアセンブリソースに従うようにして。
それで、出来たのだがどうも転置が少ない気がする。
2次元 IDCT では、縦方向と横方向で演算するのだが、MMX には必要な水平演算がない ( 隣どおしのバイトをかけたり足したりができない ) ので、どうしても行列を転置して計算する必要がある。
当然、転置したら元に戻さないと上下反転して-90度回転した ( 対角線で折り返した ) 状態になってしまうので、再度転置する必要がある。
そのため、演算前に転置して、演算後にもう一度転置する必要があるはず。
だけどそれがない。
なぜだろうと思いつつも、IDCT をコンパイルして試してみる。
やはり、絵が変。
なんだろう?
つづく……
投稿者 Takenori : 00:17 | トラックバック
Theora の MMX の IDCT その1
アセンブリのソースを見ていて不思議に思っていたのだが、なぜか上の左 4x4 と上の右 4x4 を使って計算している。
普通に考えると、MMX だから 4個単位でしか出来ないとしても、左の4列で計算して、その後右の4列でとなるはずなのだが……
転置が関係あるのか? と考えていてふと気付く。
ジグザク配列をいじって、事前に転置しているんじゃないか? と。
SMPEG のソースを眺めていた時、ジグザク配列が MMX 用に別に用意してあって、なんだろうこれ? と思っていたのだが、事前に転置するためだったんじゃないのか?
---- ジグザク配列 について ----
二次元の係数行列をそのままファイルに保存することは出来ないので、これは一度一次元に直す必要がある。
画像の場合は単純に上からか下から1行ずつ記録していくが、MPEG などの DCT 係数行列は、ジグザクに記憶していく。
例えば、4x4 の時……
00 01 02 03
10 11 12 13
20 21 22 23
30 31 32 33
のようになっているとすると、00 01 10 20 11 02 03 12 21 30 31 …… とジグザクに斜めに記録していく。
何でこんな面倒なことをしているかというと、圧縮のため。
画像を離散コサイン変換 ( DCT ) すると、周波数領域に変換される。
で、右下に行くにしたがって高周波成分になっていく。
画像の非可逆圧縮の多くは、この高周波成分を間引くことで圧縮を実現している ( 高周波成分は削っても画質への影響は少ないらしい ) 。
つまり、左上に比べて右下の方が値は小さく、圧縮率が高い時はほとんどが 0 になる。
ブロックのサイズは固定なので、係数の個数はわかっているから、0 のところは打ち切ってしまえばそのまま削れる。
大雑把に言うと以上のような理由からジグザクに記録されている。
で、これをどういう順で符号、復号化するのかがジグザク配列に書かれている。
---- 脱線終わり ----
ジグザク配列をいじれば、復号化する時にあらかじめ転置した状態で復元できるはず。
Theora のソースを探すとやはりあった。
で、配列を元にどう言う形になっているのか復元してみる。
結果、4x4 で転置され、その 4x4 の位置は変わっていなかった ( Theora のブロックサイズは 8x8 ) 。
本来転置行列は、4x4 単位で表した場合、元の行列が……
01 02
03 04
以上のようだったとすると
01 03
02 04
となるはず。
だけど、これらの位置は変わっていない。
なるほど、そういうことだったのか。
転置が少ない理由や上の左 4x4 と上の右 4x4 を使っている理由がわかった。
と言うことで、そのようにしてみるもまだおかしい。
なんだかほとんどのブロックが1色で塗りつぶされていたり、縞々だったりする。
IDCT の計算がおかしいのかなぁと何度も見直すが、Cのソースと変わりないように思える。
つづく……
投稿者 Takenori : 00:50 | トラックバック
Theora の MMX の IDCT その2
よくわからないので、ソースをいじりながらどのように結果が変わるか見てみる。
転置をなくしても結果はたいして変わっていないように見える。
IDCTをまったく行わない場合とは明らかに異なるが、似ているようでもある。
よくわからない。
ほとんどのブロックが1色で塗りつぶされていたり、縞々だったりするので、高周波成分がなくなっているような気もするのだが、そのあたりの処理を重点的に見ても間違いは感じられない。
何かケアレスミスのような気がするのだが、見つけられない。
同じような処理を繰り返すのでマクロを使っていたが、その部分を展開してデバッガで途中の結果を見てみることにした。
当然のことながら、そんな値を見ても手計算して比較しないとわからないんだけど、何かつかめるかもしれないと試す。
で、思ったのは妙にマイナスの値が多いと言うこと。
色差ならマイナスもありうるが…… 色差の後に輝度のデコードをしているのだろうか?
IDCT は何度も呼び出されるので、違うプレーンに移るまで調べるのは面倒だ。
ソースをさかのぼればいいんだろうけど、と考えていてマイナス値がどうも引っかかる。
アセンブリのコサインのテーブルは、unsigned shortでキャストしていたな。
コサイン値は、固定小数点で計算するために65536でスケールされている。
で、実際の値を見てみると、64277 や 60547、54491 などが並ぶ。
これって short ならマイナスだな。
それはまずい。
テーブル値は、64bit値にするために 0xFB15FB15FB15FB15LL てな感じにして int64 に入れていた。
これはまずそうだと __m64 に unsigned short の配列で入れておこうと思ったが、__m64 は共用体になっていて最初のメンバがunsigned short の配列ではないので、初期値を unsigned short の配列で入れられない ( __m64 が共用体だとはじめて知った ) 。
仕方ないので、unsigned short の配列にして、使用前に __m64* にキャストして代入してしまうことにした。
これでよしと思ったがダメ。よく考えたら _mm_mulhi_pi16 を使っているので signed として扱われてしまう ( 固定小数点なので下位 16bit を切り捨てるために _mm_mulhi_pi16 を使っている )。
掛け算の unsigned 版はない。
どうすれば…… ってそうか、掛ける値をもう一度足してやればいいんだ。
つまり、cos_val * a + a とする。
こうやってやれば、マイナスでない値と計算結果は同じになる。
で、動かすと綺麗に表示されるようになった。
予想外に苦労したな。
Cの時は 32bit で計算されていたから、マイナス値になっていなかったんだな。
そういえば、アセンブリソースを見ていて、足し算が多い気がするけどなぜだろうと思っていたが、このためだったのか。
命令の並び替えとかいろいろやっていてアセンブリソースは読み辛いからとそちらからソースを起こさなかったのはミスったな。
---- cos_val * a + a で結果が同じになることの説明 ----
直感的に同じになると思ってそのようにしたが、意味がわからない人用の説明を試みてみる。
似たようなことで感覚的にわかりやすいものに角度がある。
270°と -90°は同じになる。
270°は 0 ~ 360 °で表した時の値だが、これを -180°~ 180°で表現しようとしたら -90°になる。
この -90°を 270°に戻すためには、-180°~ 180°の範囲 360 を加算してやる必要がある。
つまり、-90 + 360 = 270 と言うこと。
ようはこれと同じようなことをしてやったというわけ。
コサイン値を固定小数点で計算するために 65536 でスケールするとは、0 ~ 1 の間に収まるようにコサイン値を置き換えることを意味する。
つまり、1 = 65536 ( 17bit ) と言うことになる。
で、マイナス値がどうなるかと言うのを 4ビットだけを使って2の補数であらわすと次のようになる。
−8 = 1000、−7 = 1001、−6 = 1010、−5 = 1011、−4 = 1100、−3 = 1101、−2 = 1110、−1 = 1111、0 = 0000、1 = 0001、2 = 0010、3 = 0011、4 = 0100、5 = 0101、6 = 0110、7 = 0111 ( これは、2の補数 ( Wikipedia ) の一番下の表を見てもらうとわかりやすい ) 。
この例で、もし符号なしであれば、-1 は 15 となる。
ここで説明しようとしているのは、この -1 になってしまった値を 15 に戻したいというもの。
これは、16 ( 5bit ) を足してやればいい。
上の小数部 16bit の固定少数で言えば、65536 ( 17bit ) を足してやるのと同じこと。
1 = 65536 と言う事から、1 を足してやると言っているに等しい。
cos_val * a + a で、cos_val が 0 ~ 1 の間と言う事から、cos_val が 1 の時は 1 * a = a となる。
つまり、1 を足してやるとは、a を足してやることになる。
2の補数は、上の角度の例みたいなものなので、円をイメージしているとわかりやすいかもしれない。
私の頭の中にはそのイメージがある。
トランジスタ技術SPECIAL No.48 作れば解るCPU に近い説明があったはず。
---- 以上説明終わり ----
投稿者 Takenori : 16:03 | トラックバック
Theora の MMX その他
動き補償の部分を動かすと、ここもおかしかったので修正。
バイトオーダーで、どちらが上位でどちらが下位でというのをよく勘違いしてしまう。
デブロッキングフィルタ の部分は…… 通らない?
フィルタリングレベルを上げても通らない。
と言うことで、放置していたんだけど、違う Full HD サイズの動画を再生すると画像がおかしいことに気付いた。
確かめると、デブロッキングフィルタ の部分を通っている。
どうやら、動画のフレームによって通ったりと通らなかったりするようだ。
垂直方向は問題ないようで、水平方向がおかしいようだ。
水平方向は IDCT の転置と同じような処理が入るので、その辺りが怪しいが、まだ直していない。
ベータ版の間は libtheora の中に手を入れるのはよそうと思っていたんだけど、触り始めてしまった。
MMX の部分のソースは長く触れられていないようだったので、やることにしたんだけど…… オリジナルのソース変わりませんように。
まあ、インラインアセンブラからイントリンシックに書き換えたことで、SSE2 化もやりやすくなったんだけど。
後、インラインアセンブラの cpuid 部分も イントリンシック の __cpuid に書き換えた。
これは VC 用だけど GCC にも相当する関数あるのかな?
まあ、なければインラインアセンブラのままでも GCC なら通るのでいいといえばいいんだけど。
水平方向のデブロッキングフィルタ がまだおかしいとはいえ、すべてのソースが VC でコンパイルできるようになった。
これでプロファイルをとる時、すべての関数を対象と出来るし、全体的な最適化も期待できる。
ちなみに インラインアセンブラ版と速度を比較すると Athlon 64 X2 3800 だと 3% ぐらい遅くなってしまうが、Core 2 Duo E6750 だと 2% ぐらい速くなった。
プロファイルをとって最適化するのを通せばもう少し結果は変わるかな?
まあ、それほど速度差がないようで一安心。
IDCT の部分はアセンブリソースと比べると、かなりコンパイラの最適化だよりな実装になっているので少し気になっていたんだけど。
追記:
MMX の部分変わっていないと思っていたけど 11 / 15 に変わってる……
投稿者 Takenori : 17:02 | トラックバック
2007年11月28日
逆量子化 と ジグザグ
高速化版 libjpeg では逆量子化も SIMD 化されている。
libtheora ではまだされていない。
対応すれば、少し高速化する可能性がある。
また、MPEG の方も同じように出来そうだ。
libtheora では行列の転置を ジグザグ配列を変えておくことで、行列の転置を事前にやっている。
これは、MPEG でも使えそうだ。
SSE2 化する時は独自の配列を作る必要がある。
前にまだ残っていると書いたデブロッキングフィルタの不具合は解消した。
単に書き出し時に1ドットずれていただけだった。
アセンブリのソースでその部分見逃していた。
投稿者 Takenori : 23:52 | トラックバック
2007年11月29日
MMX2 と逆量子化
libtheora で MMX2 ( 拡張 MMX ) にある丸め平均を使えばさらに高速化できるかと思ったのだが、theora の場合は四捨五入ではなく端数切捨てだった ( 丸め平均は、( a + b + 1 ) / 2 という処理を行うが、theora は ( a + b ) / 2 となっている ) 。
そのためどちらかかが奇数の時、1 誤差が発生する。
1 ぐらいかまわないと思ったのだが、誤差の発生した画像を使って後の画像が作られるせいか、誤差が蓄積し少しずつ色が変わっていき、キーフレームに到達すると元に戻るという動作をする。
明らかにこれはまずい。
で、誤差を相殺するために次のようにした。
AVG = ( a + b + 1 ) / 2;
AVG -= ( a + b ) & 0x01;
そして、これと 非 MMX2 で速度を計るとほとんど差がない。
Core 2 Duo ではわずかに遅くなっている。
Athlon 64 X2 では、少し速くなった。
Core 2 Duo の方は誤差とも言える位なので、使おうと思うが…… もう少しうまく誤差を相殺できないかなぁ。と書いていて気付いた。
初めにどちらかから 1 引いておけばいいんだ。
つまり、以下のようにする。
a -= 1;
AVG = ( a + b + 1 ) / 2;
この場合、上のものと比べて、a == 0 で b が奇数の時、1 誤差が発生するが、上のものよりも速いはず。
実際の動画で確認したところ、特に画像がおかしくなるようには感じられない。
誤差の発生条件がかなり限定されているためだろう。
わざとこの誤差が発生し蓄積されるような動画を作れば結果はかわると思うが。
計測した結果では、Athlon 64 X2 では 約 0.5 % 速くなった。
Core 2 Duo では、やはりわずかに遅くなっている。誤差ともいえるぐらいだが。
逆量子化の MMX 化対応を行ってみた。
単純に、いつも MMX側でやるようにしたら遅くなった。
DCT 係数の数が少ない時は、MMX を使わないほうが掛け算の回数が少なくなるからだろう。
と言う事で、MMX 版では 16 回掛け算が行われることから、とりあえず 20回で MMX を使うかどうかを分けてみることにした。
結果 Core 2 Duo では 約 1.5% 高速化された。より高画質で圧縮されていればさらに速くなりそうだ。
逆に Athlon 64 X2 では 約 0.5 % 遅くなった。
回数を多くすると Athlon 64 X2 側の速度低下は少なくなるが、遅いのには変わりない。
Athlon 64 X2 では、逆量子化の MMX 化は行わないほうがよさそうだ。
でも、CPU 別最適化とか入れるのはなぁ……
投稿者 Takenori : 02:32 | トラックバック
2007年12月01日
動き補償の SSE2、SSE3 化
libtheora の MMX をアセンブリからイントリンシックを使ったCに書き換えたので、ちょっと SSE2、SSE3 対応でもしてみようかなと動き補償部分の SSE2、SSE3 化を行うことにした ( SSE3 は _mm_lddqu_si128 しか使ってない ) 。
で、書き換えて計測してみると…… 遅い。
MMX 版より遅くなってる。
なぜ? と思ってプロファイルを取ってみる。
すると、SSE2、SSE3 化した関数は速くなってる。
なのに、全体では遅い。
プロファイルの結果の見方が違うのかなぁ…… なんだろうと悩みつつ、SSE3 を使わないようにしてみるともっと遅くなった。
_mm_lddqu_si128 の効果はあるようだ。
動き補償では、過去の画像の任意のブロックをコピーしてくるので、アライメントはあっていない。
SSE2 では、_mm_loadu_si128 で読み込む必要がある。SSE3 はより速い _mm_lddqu_si128 が使える。
そこで SSE2 で本当に速くなるのか見るために アルファブレンドを Core 2 Duo で計ってみた 。
結果速くなった。
なんだろう? と考えていて気付く。
メモリが遅いんだ。
確かプリフェッチがあったはずと探すと SSE に _mm_prefetch があった。
1 キャッシュ・ライン分は、32 バイトか 64 バイトらしい。
と言うこで、32 バイトとして _mm_prefetch することにした。
処理の直前でプリフェッチしても意味がないはず。
IDCT などは計算だけでメモリアクセスはない。
そこで、IDCT の次にある動き補償でアクセスするブロックを IDCT の前にプリフェッチするようにした。
速くなった。
他にもプリフェッチする場所を増やしていくと、速くなっていく。
なんてお手軽なんだ……
まあ、逆に遅くなる場合もあるので、計測しながら適切な場所に入れていく必要はあるけど。
MPEG と theora では、SIMD 化できそうな処理は、共通化できるものが多い。
とは言っても、theora で SIMD 化されているのは、IDCT と動き補償、デブロッキングフィルタ のみなのだが。
で、このうち IDCT と動き補償は共通化出来そう。
どちらかの改良が他でも活きるのはいい感じだ。
ただ、動き補償は少し違う。
theora では、単純コピー、IDCT の結果に+128したもの、IDCT の結果と合成、IDCT の結果と2ブロックの合成の4種類で、合成は切り捨て。単純コピーは、まとめて行われていて処理は分離されていない。
MPEG は、単純コピー、2ブロック合成、4ブロック合成、DCT の結果そのまま、IDCT の結果と合成、IDCT の結果と2ブロックの合成、IDCT の結果と4ブロックの合成の7種類で、合成は四捨五入。
IDCT の結果と合成は四捨五入はない。
と言ううことで、共通するのは IDCT の結果と合成のみになる。
ただ、どれも似たような処理なのである程度使いまわせる。
問題は、MMX版、MMX2版、SSE版(プリフェッチを使う)、SSE2版、SSE3版(_mm_lddqu_si128を使う)と、やたら関数が増えることだな。
10種類の関数 * 5 で 50個か…… まあ、関数によっては使わないのもあるので、だいぶ減るとは思うが多いな。
IDCT はたぶん共通化できるはず。theora のソースを見た感じでは LLM ではないようだけれど。
投稿者 Takenori : 02:37 | トラックバック
2007年12月08日
デコードのマルチスレッド化について
MPEG の動き補償部分のSSE2, SSE3化がスキップフレームを除いて出来たので、プロファイルを取ってみた。
動き補償関係の処理の割合が1/6ぐらいにまで下がったが、その代わりDCT係数のハフマンデコード周りの負荷が目立ってきた。
DCT係数のハフマンデコード + 逆量子化が40%近い割合を占めている。
現状、元のソースのテーブルを使ったデコード方法だが…… ここまでこの処理に取られていると改善した方がいいんだろうと言う気になってくる。
とはいえ、逆量子化部分は少しだけ SIMD 化できるが、他は難しい。
分岐が多いので、それを減らせば少しぐらいは向上するかなぁ。
自分の中での Theora の再生負荷の目標は、Pentium III M 866MHzで640x480の動画が再生できることと、Athlon 64 X2 3800+ でフルHD動画を再生できること。
PenIII の方はギリギリだけれど、再生できるぐらいのはず。
Athlon 64 X2 3800+ のフルHDは全然無理。
Core 2 Duo E6750 で音なしがギリギリ再生できると言うところ。
Core 2 Duo E6750 が Athlon 64 X2 3800+ の倍程度と言うことを考えると、マルチスレッド化は必須だろう。
マルチスレッド化出来そうなのは、動き補償とIDCT部分かな。
IDCTは、係数さえデコードされていれば独立しているし、動き補償は他のフレームを参照して合成コピーするだけ。
最初にブロック情報をまとめてデコードして、そのブロックのキューからIDCTと動き補償を実行するスレッドを走らせればいい。
ブロック情報のデコードも別スレッドの方がいいかな? まあ、その辺りはパフォーマンスが出るように試行錯誤か。
ブロック情報がまとまっていれば、次のブロックがわかるためプリフェッチしやすいので、メモリアクセスもある程度改善できると踏んでいる。
MPEG も同様の方法でマルチスレッド化できるが…… 必要だろうか?
マルチスレッド化によって高速化されれば、再生時の応答速度が向上するか。
後、機能性を出すためにも速い方がいいといえばいいか。
まあ、やれそうならやるかな。
なんか思っていたよりも時間かかっていると言うかかけているというか。
高速化にはまりすぎだな。
投稿者 Takenori : 15:26 | トラックバック
2007年12月16日
メモリのアライメント
SSE や MMX を使う時、メモリがアライメントされていないとダメなケースがあったり、アライメントされていないと遅かったりするので、メモリをアライメントする。
が、アライメントしたはずなのにうまくいかないケースに出会ったのでメモしておく。
初め、以下のようにしてアライメントさせていた。
dct_coeff = new __declspec(align(16)) short[64];
new __declspec(align(16)) でアライメントしてくれると言う確証はなかったが、このようにしてうまくいったのでそうしていた。
が、デバッガで動作させると SSE2 を使うところで落ちる。
デバッグなしで動作させると問題ない。
デバッガの有無で異なることに気付くのに時間がかかったが、それに気付いた後、上の方法ではなく自前でアライメントすることにした。
以下のような感じ。
const unsigned a = 16;
unaligned = new char[128+a-1];
dct_coeff = (short*)((unsigned)(unaligned + a - 1) & ~(a-1));
当然開放時は、unaligned を delete する。
でも、これだと2個変数を管理しないといけないので面倒くさい。
これは、確保するサイズを + sizeof(void*) とでもして、ポインタ分多く確保し、そこに元のアドレスを入れておけばいい。
つまり、以下のような感じ。
→new が返したアドレス
→アライメント後のアドレス - sizeof(void*) ここにnewが返したアドレスを入れておく。
→アライメント後のアドレス。このアドレスを返す。
当然、この時アライメント後のアドレス から new が返したアドレス を引いたサイズは sizeof(void*) より大きくないといけないので、そうなるようにアライメントする必要がある。
具体的には new が返したアドレス + sizeof(void*) のアドレスをアライメントすればいい。
後、__m128型をメンバに持つ構造体・クラス によると、Visual Studio 2005 ではアライメント関係でバグがあるようだ。
で、アライメントされたメモリの確保方法として、_aligned_malloc と _aligned_free を使う方法が書かれている。
VC ならメモリ確保にこれを使うのが楽そうだ。
投稿者 Takenori : 18:31 | トラックバック
2007年12月18日
メモリのアライメント2
アライメントされたメモリアロケータにトラックバックされていた。
久しぶりのトラックバックなのでうれしくなって少しだけ書く。
メモリのアライメントの続き。
dct_coeff = (short*)((unsigned)(unaligned + a - 1) & ~(a-1)); の式自体は、アセンブラ画像処理プログラミング―SIMDによる処理の高速化 に書かれているものそのままのはず。
また、-1のところに保存しておくソースは、吉里吉里2のソースのここら辺 にある。
最終的には、#ifdef で切り替えて、VC なら _aligned_malloc と _aligned_free を使うと思う。