2007年12月17日
メモリのアロケート malloc について
PC でプログラムを組んでいると malloc/free や new/delete がどのようにメモリを確保したり開放したりしているのか気にする機会はほとんどないが、組み込み関係だと時々メモリアロケートの問題に悩まされる。
メモリ管理のアルゴリズムは、ファーストフィットやベストフィットなどいくつかある。
ファーストフィットは、空きメモリリストで最初に見付かったメモリブロックを返す。
ベストフィットは、空きメモリリストの中で最もサイズの近いメモリブロックを返す。
一見ファーストフィットの方が速そうだが、メモリの断片化が進みやすく、メモリブロックの数が増えることから常に速いとは限らない。
逆にベストフィットはメモリの断片化が起きづらく、メモリブロックの数を抑えられる。
私の中では以上のような認識だが、malloc/free の呼び出し順やサイズなど利用状況によって状況は変わる。
4 メモリマネジメント のページでは、ベストフィットは使い物にならないとても小さな領域を増やす結果 につながって利用効率が落ちるとある。
でも、実際のプログラムで確保するメモリのサイズの種類は多くの場合限られており、ほとんど固定サイズを確保したり開放したりするだけなので、ベストフィット が効率良いと思っている。
まあ、それはいいとして具体的なアルゴリズム。
ベストフィット で基本的にこう言う仕組みという認識を元に書いてみたソースが以下の通り。
テストはしていないので、もし使うのならきちんとテストした方が良い。
|
//! @file MemoryManager.h #ifndef NULL //! メモリの確保がコールされた時、返すメモリのアドレスの前に管理領域を付けて返す //! メモリマネージャ MemoryBlock* free_list_; public: #endif // __MEMORY_MANAGER_H__ |
|
//! @file MemoryManager.cpp #include "MemoryManager.h" //! アドレス型 環境に応じて変える //! 初期化する MemoryBlock* bestfit = NULL; // 最も近いサイズのメモリを分割して返す // 指定されたサイズ以上の空きブロックがなかった // つなげられるメモリがなくなるまで繰り返す // 隣接するメモリがないか検索する if( connected == 0 ) { |
アルゴリズムがわかりやすいように書いたので、効率は悪いかもしれない。
このソースを読めばどのような仕組みかはわかると思う。
投稿者 Takenori : 00:48 | トラックバック
固定サイズメモリのアロケート
メモリのアロケート malloc について で malloc のアルゴリズムについて書いたが、見るからに遅そうだ。
サイズが固定の場合、より高速にメモリの確保と開放が出来る。
ソースは以下のような感じ。
これまたテストしていないので、使う場合はテストした方がいい。
|
//! @file ArraiedAllocator.h #ifndef __ARRAYIED_ALLOCATOR_H__ template< int TTypeSize, int TNumArray> public: template< int TTypeSize, int TNumArray> template< int TTypeSize, int TNumArray> template< int TTypeSize, int TNumArray> template< int TTypeSize, int TNumArray> #endif // __ARRAYIED_ALLOCATOR_H__ |
ソースは見るからに単純で速そう。
まあ、サイズが固定だからなのだが。
投稿者 Takenori : 01:07 | トラックバック
メモリアロケートを計ってみる
メモリのアロケート malloc について や 固定サイズメモリのアロケート を書いたついでに、少し時間を計測してみた。
ただ、単純に100万回メモリ確保して、100万回メモリ開放しただけなので、まったく当てにならない。
実際の利用状況では、可変の時断片化され、もっと遅くなるはず。
ということで Athlon 64 X2 3800+ で測った結果。
VC2005 の malloc 420 ミリ秒
固定サイズ版 14 ミリ秒
可変版 33 ミリ秒
固定サイズはやはり速いな。でも、標準の malloc が思ったよりも遅いが、仮想記憶とかいろいろとやることあるだろうから仕方ない。 ※ 追記参照。
でも、100万回やってこの時間。
PC では、開発効率や安全性を考えると無視してもいい時間だろう。
というか、PC では自分で書いたのを使う気にはなかなかなれない。
可変内でいくつかの固定サイズを持ち、それらを振り分けるなどすると小領域の時の速度は大きく改善されるはず。
確保や開放のログを取り、その傾向から適した方法を選ぶのが良いと思う。
とは言っても、メモリの確保や開放の速度が問題になることはほとんどなく、どちらかといえば断片化によりメモリが枯渇してしまうことへどう対処するかの方が問題なのだが。
3:30 追記
排他制御のことを忘れていた。
他スレッドから呼ばれても大丈夫なようにロックする処理が重いということのようだ。
投稿者 Takenori : 01:42 | トラックバック
2008年02月21日
テクスチャマッピング アルゴリズム 最大最小法
テクスチャマッピングのアルゴリズムはいくつかあるが、その中で昔速いと言われていたらしい方法に最大最小法がある。
まずはポリゴンを塗るだけのことを考えるとする。
これはまず高さ分のX軸値の最大値と最小値を保持するバッファを用意する。
次に、最大値に最小値を、最小値に最大値を入れて初期化する ( int なら INT_MAX や INT_MIN ) 。
後は、各ポリゴンの辺についてY座標が小さい方から大きい方へ見ていき、現在のY座標値のX座標値が最大値よりも大きければ最大値バッファに値を入れる。また、最小値よりも小さければ、最小値バッファに値を入れる。
このようにして3辺処理すると、各Y座標値について、X座標の最小値と最大値が入る。
これを図にすると以下のようになる。
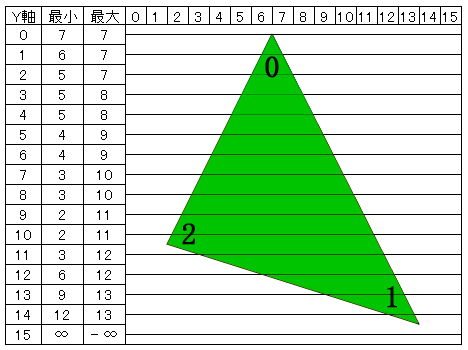
上図のようにX座標の最小値と最大値がわかれば、後はこの間を塗ればポリゴンが描ける。
Y座標の変化に従ってX座標値がどのように変化するかを調べるには、昔はブレゼンハムが使われていたようだ。
普通に考えるのなら、単純にY値の比で求めればいい。
つまり、Yの変化量 / 高さ が、現在のY値を比であらわしたもの。 0.0 ~ 1.0 の値になる。
後はこれを幅にかけてやれば、現在のY値の時の、Xの変化量がわかるので、Xの始点座標値に加算してやれば、現在のX座標値が求まる。
ただ、毎回割り算や掛け算していると重いので、Y軸値が1増えた時の変化量をあらかじめ求めておき、後はY軸値が変化するごとに、その変化量を加算していけば結果は同じになる ( 誤差の影響を無視した場合 ) 。
これでポリゴンが描けたとして、テクスチャマッピングの場合はどうするか?
これも考え方は同じ。
まず、各頂点の 0 ~ 2 のそれぞれにテクスチャのUV座標値を持たせる。
その後は、先ほどのX座標値の補間と同じ、Y軸値が1増えた時にU ( V ) 座標値の変化量を求めて、加算していってやれば、各Y軸値の時のUV座標値が求まる。
求まったUV座標値は最大値と最小値を保持するバッファにUV座標値も保持するようにして、そこに入れておく。
こうすればX座標の最小値と最大値とそのUV座標値がわかる。
ポリゴンの時は単純に1色で塗ったけど、テクスチャの時は、X座標値が最小値から最大値まで変化する時のUV座標値を補間しながらUV座標を求め、テクスチャ画像からそのUV座標値のピクセルをコピーしてやればいい。
この時の補間も先ほどY軸でやった方法と同じ考え方で出来る。
この方法は比較的わかりやすく、昔は速かったらしいのだが、最近は分岐があると遅いので、遅くなってしまうようだ。
投稿者 Takenori : 17:57 | トラックバック
テクスチャマッピング アルゴリズム 毎ライン交差判定
テクスチャマッピングでポリゴンの辺を基準にするのではなく、スキャンラインを基準として、各 Y 座標値で各辺と交差判定し、その間を補間しながら描画する方法がある。
まず、以下の図のようなポリゴンがあったとする。
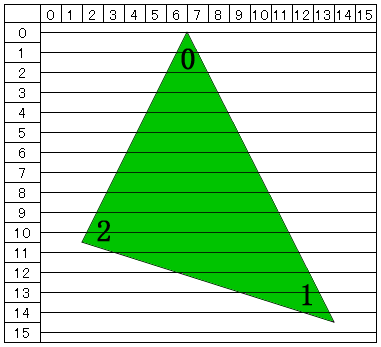
最初に全ての頂点で Y 軸の最小値と最大値を求める ( 図では 0 と 14 が当てはまる ) 。
次にこの Y 軸の最小値から最大値までのスキャンラインで交差判定していく。
交差判定は単純に、辺 0-1、辺 1-2、辺 2-0 の順で行い、最初に交差した2点間を描画する。
交差するかどうかの判定は、単純に 2 頂点の Y 軸値の間に現在のスキャンラインの Y 軸値が入っているかどうかで判定できる。
交差していた場合は、その Y 座標値での、X 座標値と UV 座標値を求める。
辺 0-1 間なら、k = ( y - y0 ) / ( y1 - y0 ) で Y 座標の比を求める。
後は、これを用いて計算する。
x = x0 + k * ( x1 - x0 );
u = u0 + k * ( u1 - u0 );
v = v0 + k * ( v1 - v0 );
このようにして求めた X 座標値と UV 座標値は、右か左端のどちらかの 1 点となる。
同様にして、辺 1-2、辺 2-0 と順に交差判定と計算を行い、最初に交差した 2 点を使う。
交差した 2 点は、右左がわからないので、X 座標値で大小判定し、左と右を決定する。
後は X 座標値が小さい方 ( 左 ) から、大きい方へ向かって、UV 座標値を補間しつつ、テクスチャ画像のその UV 座標からピクセルを現在の XY 座標にコピーしていけばいい。
この時上の Y 座標値のように計算していたのでは重いので、X 座標値が 1 増えると UV 座標値がいくら増えるか求めて、後はその変化量を加算して行って求める。
毎ライン交差判定するので重そうだが、思っているよりは軽い。
また、毎ライン交差位置を計算するので、誤差は軽減される。
投稿者 Takenori : 20:08 | トラックバック
テクスチャマッピング アルゴリズム 辺沿いに描画
ポリゴンの頂点を右、もしくは左回りに格納して、その格納順から辺の位置を求め描画する方法がある。
以下の図のようなポリゴンがあったとする。
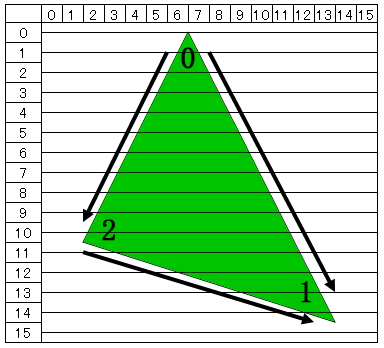
まず最初に全頂点の中で一番上の頂点を探す ( この図では 0 番 ) 。
次に頂点が右回りに格納されているとしたら、頂点番号を -1 した頂点が左方向になる。
図では、-1 になるが、頂点数は 2 なので、if( vtx < 0 ) vtx = 2; という具合にして、循環するようにする。
そして、この辺で Y 軸値が 1 変化した時、X 座標値や UV 座標値がいくら変化するかを求める。
次に、頂点番号を +1 した頂点が右方向になる。
この辺も同様に Y 軸値の変化量と X 座標値、 UV 座標値 の変化量の関係を求める。
こことまできたら後は、Y 軸値を上から下へ変化させながら、左右の辺の X 座標値と UV 座標値を求めていく。
求まった、X 座標値と UV 座標値を使って、そのスキャンラインを X 座標値が小さい方から描画していく。
この時右か左は既にわかっているので、左右の判定の必要はない。
そして、現在のスキャンラインがどちらかの辺の下端に達したら、辺を変える。
左辺なら -1、右辺なら +1 すればいい。
辺が変わったら、再び Y 軸値の変化量と X 座標値、 UV 座標値 の変化量の関係を求める。
このようにしてスキャンラインが一番下の頂点まで達したらポリゴンが描画できている。
辺が初めから右か左かわかっていること、途中の X 座標値と UV 座標値は加算によって求められていることから、この方法ではかなり高速に処理できる。
投稿者 Takenori : 20:41 | トラックバック
2D テクスチャマッピング アルゴリズムについて
テクスチャマッピング アルゴリズムについていくつか書いた。
テクスチャマッピング アルゴリズム 最大最小法
テクスチャマッピング アルゴリズム 毎ライン交差判定
テクスチャマッピング アルゴリズム 辺沿いに描画
ただ、これらのアルゴリズムは 2D での話。
3D で用いようとしたら、Z 座標値 も考慮する必要があります。
そうしないとテクスチャがひずんでしまいます。
なぜうまく行かないかは簡単にわかります。
縞々の床があったとします。
これを上述の方法で描画すると以下のようになります ( 適当に描いたのでこの通りではないかも ) 。

どう見ても縞々の台形です。
まあ、多少の錯覚と経験的なものから、床だといわれれば、まあ床かなと。
でも、実際は遠くに行くほど横縞の感覚は狭くなっていくはずです。
それなのにこの図では等間隔に並んでいます。
なぜ等間隔かといえば、単純にY軸値を補間しているだけだからです ( Y軸値が 0 ~ 1まで均等に変化するものとしているため ) 。
これを 3D 的にしようとしたら、遠くほど Y 軸値に対応した変化量を大きく、近くほど小さくする必要があります。
このような処理はパースペクティブコレクトなどと言われています。